Försvar på djupet: Del 3 Klienter och sessioner
19 September 2023I de två första artiklarna har vi diskuterat hur du kan designa ditt system för att bygga en stark behörighetskontroll. Vi har tittat på hur du hittar rätt balans för vilken information som knyts till din access token och balansen mellan identitet och lokala behörigheter. Denna artikeln kommer handla om hur en klient kan konfigureras för att få tag på din token, samt hur vi hanterar sessioner.
Vi börjar med att dela upp våra klienter i olika typer:
- Service integration (maskin till maskin)
- Web (både SPA och server-side)
- Native (iOS, Android, Windows, Linux, macOS etc)
- Devices (klient utan webbläsare, eller med dålig möjlighet att skriva in ett lösenord tex TV och terminaler)
Från OAuth2 specifikationen behöver vi idag bara välja från tre olika flöden som täcker samtliga typer av klienter.
- Client Credentials (Service integration)
- Code+PKCE (Web och Native)
- Device Code (Devices)
Client Credentials representerar en klient där en människa inte är inblandad, tex en annan tjänst eller ett automatiserat jobb.
Code+PKCE används för alla klienter som används av en människa och som har en webbläsare.
Device Code används om klienten saknar webbläsare, eller har dåliga möjligheter för användaren att mata in text. Exempel är TV, terminaler (CLI) etc.
Martin Altenstedt, Omegapoint
Att det “bara” är tre flöden är en väsentlig förenkling jämfört med ett par år sedan och underlättar för mig som jobbar med detta. Jag kan verkligen rekommendera att du som är ansvarig för identitet och inloggning läser på lite om dessa tre flöden. Här är ett par bra länkar:
https://datatracker.ietf.org/doc/html/draft-ietf-oauth-v2-1-02
Service integration
Klienter där en människa inte är inblandad är en viktig komponent i mer komplexa system. De system som byggs idag består i allt större utsträckning av löst kopplade tjänster. Kommunikation mellan dessa tjänster skapar behov av denna typ av integration. Ett annat exempel är automatiserade systemtest av driftsatta system. Den process som utför testerna i en pipeline för kontinuerlig integration (CD/CI) är en klient av denna typ.
Dessa klienter representerar ofta en privilegierad användare som har stora rättigheter i systemet. Det är viktigt att vår behörighetsmodell och scopes är tillräckligt bra för att kunna begränsa rättigheterna för denna typ av klienter. Särskilt systemtestklienter är problematiska, eftersom de har behov av tillgång till hela systemet.
Erica Edholm, Omegapoint
Jag ser ofta testklienter som har fullständiga rättigheter till systemet vilket är ett problem när det brister i hanteringen av client secret.
Dessutom tappar man en massa testfall när vi har en testklient som har rätt till allting. Det är bättre att ha flera testklienter med mer specialiserad behörighet till systemet.
Ännu sämre är om man stänger av hela eller delar av behörighetskontrollen för system i test! Dels kan det leta sig ut i produktion, dels testar man faktiskt inte koden som går i produktion.
När vi designar systemet behöver vi tänka på testbarheten :-)
Flödet som vi använder heter “Client Credentials”, och är det enklaste av våra tre OAuth2 flöden.
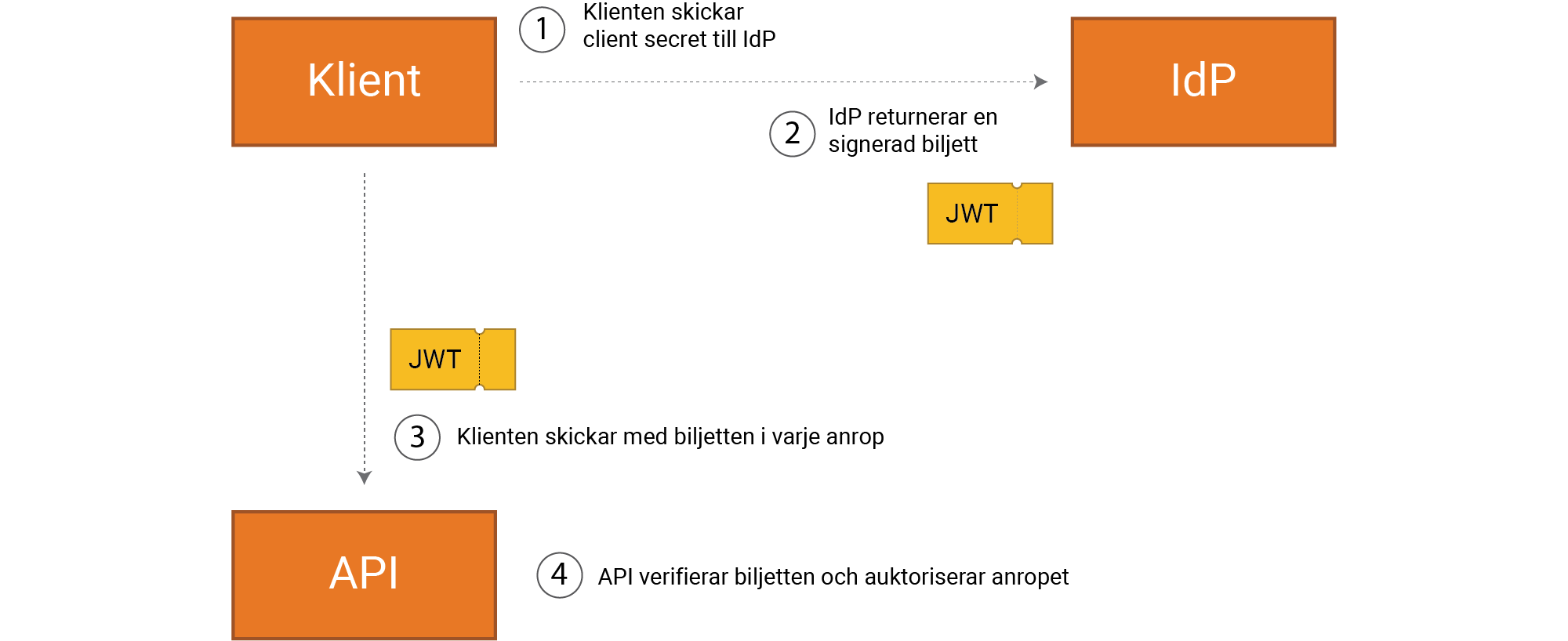 Klienten autentiserar sig med en “client secret” och får en access token (t ex
en JWT) som kan användas för alla API anrop.
Klienten autentiserar sig med en “client secret” och får en access token (t ex
en JWT) som kan användas för alla API anrop.
Sättet klienten autentiserar sig på är vanligtvis med hjälp av en “client secret”, eller med ett X.509 certifikat. En mycket viktig aspekt av “client secret” är att det genereras maskinellt med mycket hög entropi. Den har alltså inte de svagheter som ett lösenord som en människa väljer själv har.
Om vi väljer att låta klienten autentisera sig med ett certifikat så kan vi öka säkerheten med certifikatsbundna tokens, vilket gör att klientens access token knyts kryptografiskt till certifikatet och därmed endast kan användas av en klient som har tillgång till certifikatets privata nyckel (till skillnad från en access token som inte är bunden till ett certifikat och kan användas av vem som helst).
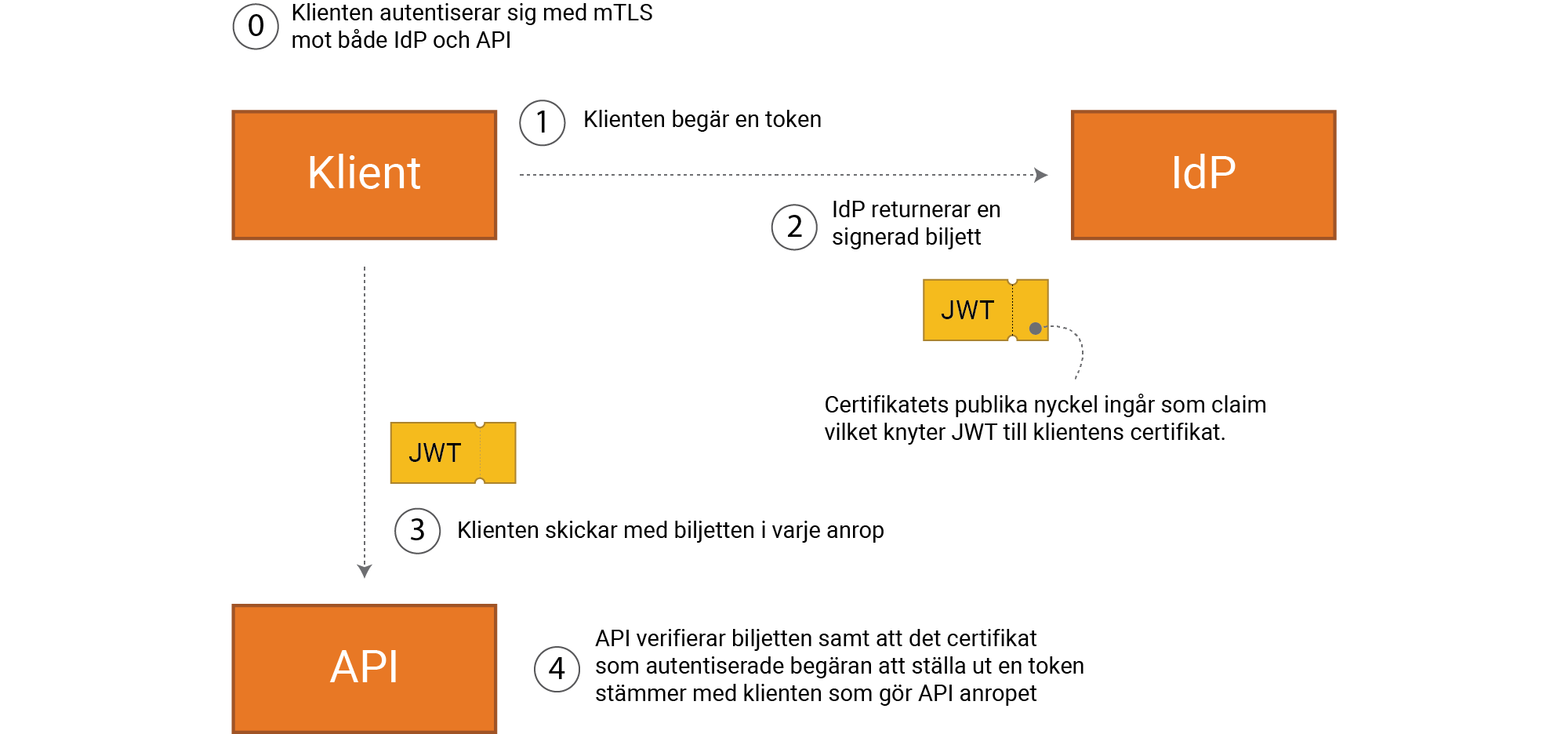 Om klienten använder ett X.509 för autentisering via mTLS och access token
formatet är JWT, kan informationen om klientens certifikat läggas till
som ett claim.
Om klienten använder ett X.509 för autentisering via mTLS och access token
formatet är JWT, kan informationen om klientens certifikat läggas till
som ett claim.
API kan sedan använda denna information för att säkerställa att access token skickas från samma klient (den klient som har tillgång till den privata nyckeln).
Nackdelen är att vi behöver hantera X.509 certifikat, vilket kan vara mer komplext jämfört med hantering av “client secret”.
Notera att vi kan slippa hanteringen av certifikat men ändå binda tokens till en klient genom att generera certifikat på klienten per session. Dessa certifikat använder vi endast för att knyta en token till klienten via mTLS. Med andra ord använder vi då inte certifikatet för att autentisera klienten i OAuth2 flödet.
Det är viktigt att kunna rotera både certifikat och “client secret” samt att förmedla dessa till klienten på ett säkert sätt. Detta är enkelt att säga men kan i praktiken vara en stor utmaning för en organisation.
Martin Altenstedt, Omegapoint
Ett vanligt problem är att “client secret” och certifikat för systemklienter inte hanteras på ett säkert sätt. De kan t ex checkas in tillsammans med klientens källkod, skickas per mail, SMS eller chat. I kombination med att de representerar privilegierad tillgång till systemet kan det representera en allvarlig säkerhetsbrist.
Ytterligare ett är att secrets inte roteras, vilket ökar risken för att en före detta anställd eller angripare kan nå systemen. Det är viktigt att designa sina system så att det är lätt att återkommande rotera secrets
För att stärka skyddet ytterligare kan vi även använda oss av en reference token istället för en full JWT som access token.
En JWT innehåller all information som vårt API behöver för att göra en behörighetskontroll. Problemet med en JWT är dels att den inte kan annulleras samt att den ofta innehåller persondata. Detta är extra viktigt att tänka på om klienten representerar en privilegierad användare, utvecklas av en tredje part eller är publik.
Vi bör fundera på att stärka skyddet för serviceintegrationer ytterligare med hjälp av reference token, istället för en JWT. Som alltid är detta en balans mellan säkerhet och systemprestanda.
 Klienten autentiserar sig med en “client secret” och får en access
token i form av en reference token som kan användas för
alla API anrop.
Klienten autentiserar sig med en “client secret” och får en access
token i form av en reference token som kan användas för
alla API anrop.
En reference token innehåller inte någon information och erbjuder ett starkare skydd jämfört med en full JWT eftersom den kan annulleras omedelbart. Nackdelen är ett extra anrop från API till IdP för att slå upp en full JWT vid varje anrop. Notera att anropet måste vara autentiserat.
Nu har vi etablerat en grund som vi kan använda i alla våra flöden. Vi kan stärka vårt skydd genom att använda ett par olika mönster:
- mTLS (X.509) istället för “client secret”
- Certifikatsbundna tokens (kräver mTLS, både till API och IdP)
- Reference token istället för JWT
Tobias Ahnoff, Omegapoint
Även om en klient har tillgång till flera scopes så behöver vi tänka på att använda så få scopes som möjligt. Detta är extra viktigt när tokens skickas till tredjeparts tjänster som du inte kontrollerar, vad hindrar den tjänsten från att använda din token mot andra tjänster? Principen “Least Privilege” gäller även för tokens.
Webb
Oavsett om det gäller en Single Page Application (SPA), eller om det är HTML som skapas på servern och serveras till webbläsaren, gäller samma flöde: Code+PKCE. Resten av detta avsnitt kommer att diskutera fallet med en SPA, eftersom vår erfarenhet är att det är det absolut vanligaste sättet att bygga webbapplikationer idag.
Rekommendationen från IETF är att använda en Backend For Frontend (BFF) som klient till IdP. Det betyder att vår SPA (frontend) bara pratar med BFF (backend) som är en proxy till alla API. Autentisering mellan SPA och BFF är med cookie. BFF översätter cookie till access token som den skickar med i alla API anrop. Det är BFF som hanterar alla tokens och ansvarar för att rätt token används i rätt sammanhang.
Att integrera direkt från webbklienten till IdP med hjälp av tex oidc-client-js, auth0-js eller liknande bibliotek är allt mer problematiskt. I takt med att webbläsare förstärker skyddet för den enskilde individens data så begränsas våra tekniska möjligheter att bygga en bra lösning hjälp av dessa bibliotek.
https://tools.ietf.org/html/draft-ietf-oauth-browser-based-apps-05#section-6
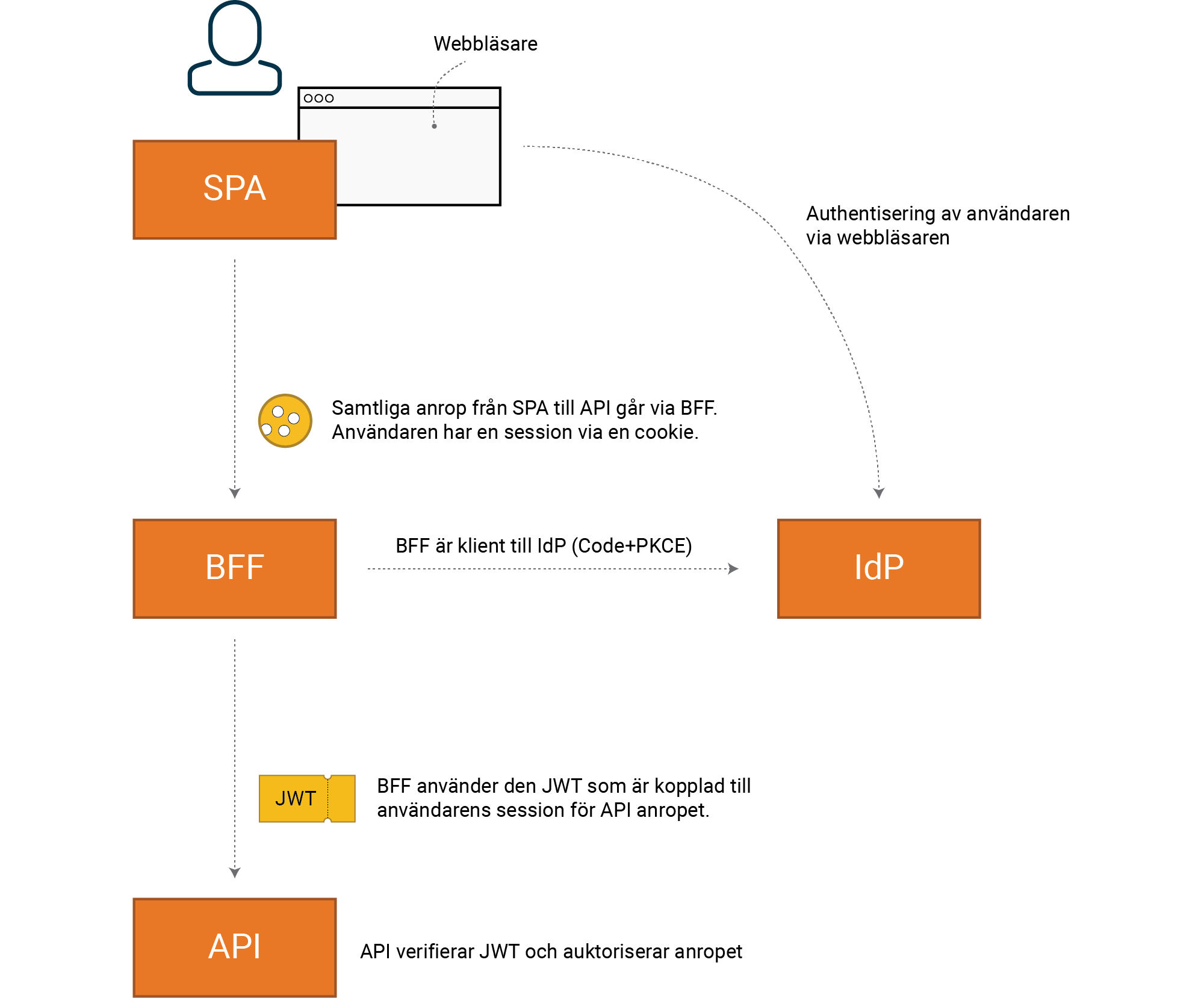 Det är BFF som är klient mot IdP, inte vår SPA. Korrekt flöde för integrationen
till IdP är Code+PKCE.
Det är BFF som är klient mot IdP, inte vår SPA. Korrekt flöde för integrationen
till IdP är Code+PKCE.
Notera att du kan stärka skyddet med hjälp av reference token och certifikatsbundna tokens enligt samma mönster som vi beskrev i kapitlet innan om serviceintegration. Jämfört med en direkt integration mellan SPA och IdP, ger oss en BFF möjligheter till ett mycket starkt skydd då det för med sig att tokens endast hanteras i en miljö vi kontrollerar (backend).
Använd ett ramverk som ger dig bra stöd för att bygga en BFF. För säkerhetskritiska funktioner vill vi basera våra lösningar på härdade komponenter, väletablerade mönster och referens implementationer. Säkerhet är helt enkelt ett område där du bör undvika att uppfinna egna lösningar.
Se kapitel Sessioner nedan för mer information om hur vi behöver hantera cookies och tokens för att användaren ska kunna använda applikationen över en längre period.
Native
Exempel på native klienter är mobilappar i iOS och Android, samt installerade program i Windows, macOS och Linux. Formellt menar vi en klient som är publik, kan dekonstrueras av en angripare. Jämför med en konfidentiell klient, tex vår BFF, som en angripare inte har tillgång till och därför kan anförtros hemligheter. Många native klienter har goda möjligheter att lagra en hemlighet, men med viktiga förbehåll.
Även om en plattform som tex iOS har möjligheter att lagra en hemlighet på ett kryptografiskt säkert sätt, så kan en attackerare som har tillgång till miljön när klienter körs extrahera hemligheter direkt ur minnet för klienten. Olika plattformar har olika starka skydd, men av detta skälet så kan det finnas anledning att använda reference tokens eftersom de, till skillnad från en full JWT aldrig innehåller något persondata och kan annulleras omedelbart.
Flödet som klienten ska använda är Code+PKCE. Vi använder systemets webbläsare för autentisering mot IdP. Som alltid bör vi använda färdiga bibliotek för integrationen med IdP. Alla stora plattformar har denna typ av färdiga bibliotek. Välj det som har bäst stöd för just ditt scenario.
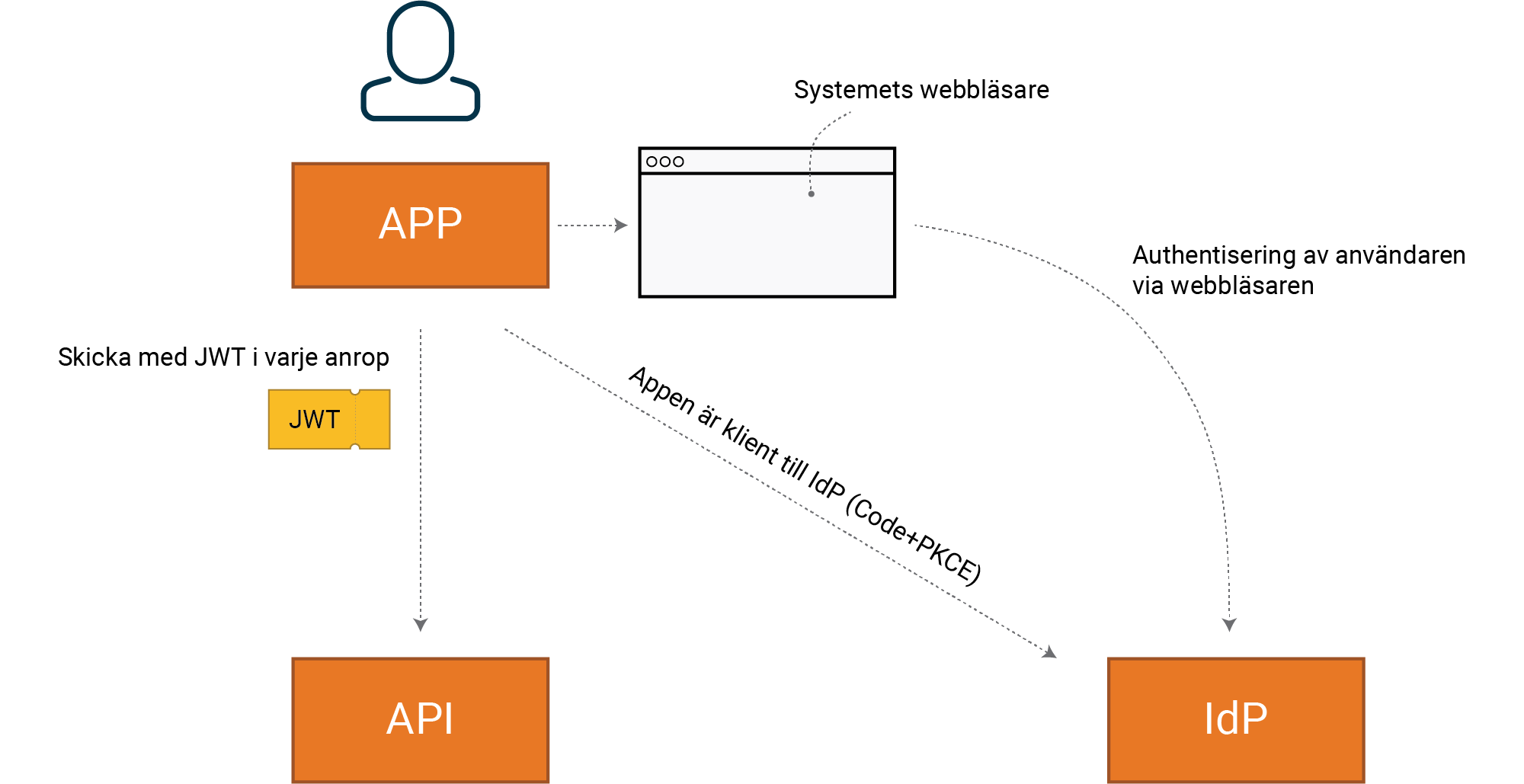 Klienten använder systemets webbläsare för att låta användaren autentisera sig
mot IdP. Vi använder oss av ett färdigt bibliotek från leverantören av
plattformen.
Klienten använder systemets webbläsare för att låta användaren autentisera sig
mot IdP. Vi använder oss av ett färdigt bibliotek från leverantören av
plattformen.
Tobias Ahnoff, Omegapoint
Vi stöter ofta på en motsättning mellan bra interaktionsdesign för användaren och säker MFA. Speciellt gäller detta i mobilappar där det är lockande låta användaren ange lösenord direkt i appen istället för att öppna systemets webbläsare. Här är det viktigt att förstå användarens perspektiv och möjligheterna som OAuth2 och OIDC ger oss. Vi vill hitta en bra balans mellan tillgänglighet och konfidentialitet.
Devices
När vi har klienter som saknar webbläsare, eller har ett begränsat stöd för att låta en användare skriva in text, kan vi använda oss av ett flöde som heter “Device Authorization Grant”. Exempel på klienter är TV apparater och IoT devices. En viktig typ av klient i många system är en terminal (CLI) där detta flöde kan vara ett mycket smidigt sätt för användaren att autentisera sig på.
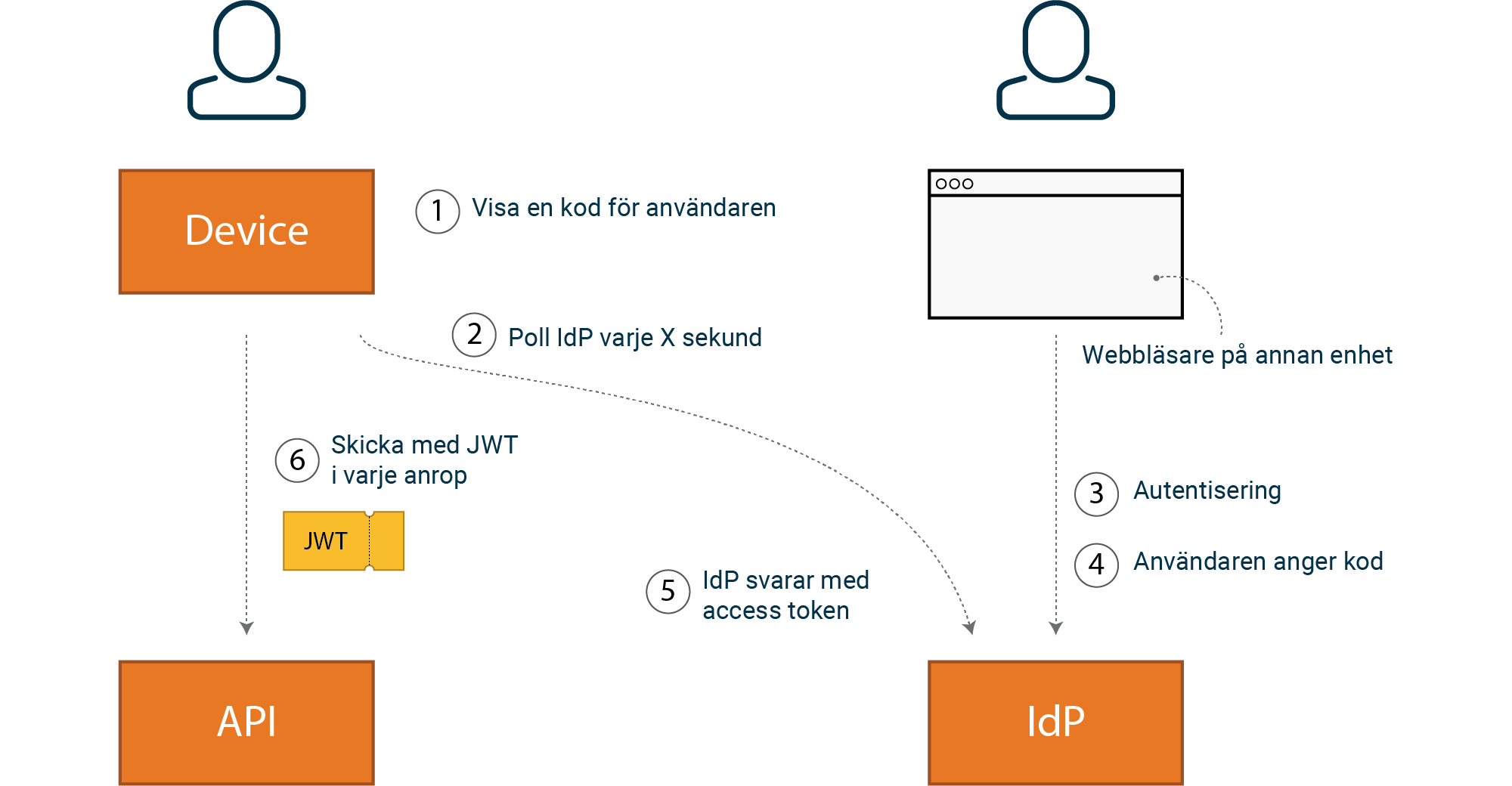 En användare startar inloggningen i tex en bash prompt. Inloggningskommandot
returnerar en webbadress och kod som samma användare kan använda för
autentisering på en annan enhet.
En användare startar inloggningen i tex en bash prompt. Inloggningskommandot
returnerar en webbadress och kod som samma användare kan använda för
autentisering på en annan enhet.
[anna@machine ~]$ signin
To sign in, use a web browser to open the page
https://idp/device and enter the code C7HL4EQK4 to authenticate
Användaren startar en webbläsare, navigerar till länken ovan och autentiserar sig som vanligt. Efter en lyckad inloggning anger användaren koden, vilket gör att en access token returneras till klienten (Device).
Summering klienter och flöden
Nu har vi gått igenom hur olika typer av klienter får tag på access tokens. Vi har fyra olika klienttyper och tre grundflöden med OAuth2.
| Klienttyp | Flöde |
|---|---|
| Service integration | Client Credentials |
| Web | Code |
| Native | Code |
| Devices | Device Code |
Oavsett flöde kan vi stärka vi skyddet med mTLS för stark klientautentisering, certifikatsbundna tokens och reference tokens.
Martin Altenstedt, Omegapoint
Ett viktigt arkitekturellt beslut är att vi använder BFF för SPA:s. Det finns många säkerhetsmässiga fördelar med en BFF-lösning, då vi håller säkerhetskritisk kod och tokens backend.
Code-flödet skall alltid säkras med PKCE och för system med högre säkerhetskrav bör även PAR användas, vilket rekommenderas genom t ex FAPI.
PAR är en ny specifikation som förväntas få stöd under hösten 2021. PAR stärker skyddet genom att minimalt med parametrar går via webbläsaren.
https://datatracker.ietf.org/doc/html/draft-ietf-oauth-par-08
FAPI kommer ursprungligen från Bank och finans-sektorn men i och med arbetet med 2.0 så gäller rekommendationer även system som har behov av samma säkerhetsnivå “financial grade api:s”, t ex Hälsa och sjukvård.
Tobias Ahnoff, Omegapoint
Oavsett nivå av säkerhet är FAPI en utmärkt referens för hur man bör bygga säkra OIDC/OAuth2 implementationer. Med tydliga krav och rekommendationer för både IdP, klient och API (resursserver).
Sessioner
OAuth2 definierar endast delegering av auktorisation till en klient, d v s hur man på ett säkert sätt kan ge klienten en access token. Grundscenariot för OAuth2 är att användaren ger tillgång till t ex profildata från sitt Google-konto till en tredjepartsklient, ofta även efter att användaren har lämnat applikationen.
Styrkan med OAuth2 Code-flöden är att detta sker utan att användaren avslöjar sin hemlighet för tredjepartsklienten. Hemligheten, i det här fallet Google-lösenordet, skall stanna mellan Google och användaren.
Detta är dock inte samma sak som att en användare loggar in hos klienten och har en aktiv session.
En session kan definieras som ett temporärt och interaktivt utbyte av data mellan en användare och systemet. Sessionen etableras vid någon tidpunkt och avslutas vid ett senare tillfälle. Sessionens livslängd varierar beroende på typ av system. En bankapplikation har typiskt korta sessioner, medan t ex ett administrativt system har betydligt längre.
En annan viktig del av en användares session är att vi har ett standardiserat sätt att representera användarens identitet. För detta använder vi OpenID Connect (OIDC), som standardiserar identitet och till viss del också hur sessioner och Single Sign-On, samt Single Logout, hanteras.
Martin Altenstedt, Omegapoint
Innan OIDC blev etablerat var det många som gjorde sin egen inloggningslösning baserat på OAuth2,vilka ofta haft svagheter, exempelvis Facebook, Apple etc. Att uppfinna egna lösningar här är helt enkelt ingen bra idé, inte ens om du är ett stort företag.
OIDC används ovanpå OAuth2, d v s det är fortsatt samma Code-grundflöden för delegering av auktorisation, och med en OIDC-lösning har vi tre olika typer av tokens:
- Id tokens ger klienten möjlighet att validera autentiseringen av användaren och dennes identitet
- Access tokens använder klienten för att göra anrop till tjänsten (ofta ett API)
- Refresh tokens kan klienten använda för att begära ut en ny access token från IdP, utan att användaren återautentiserar sig och på så sätt hantera långlivad tillgång till användarens resurser
Med en SPA implementerad enligt BFF-mönstret som exempel ser det ut så här:
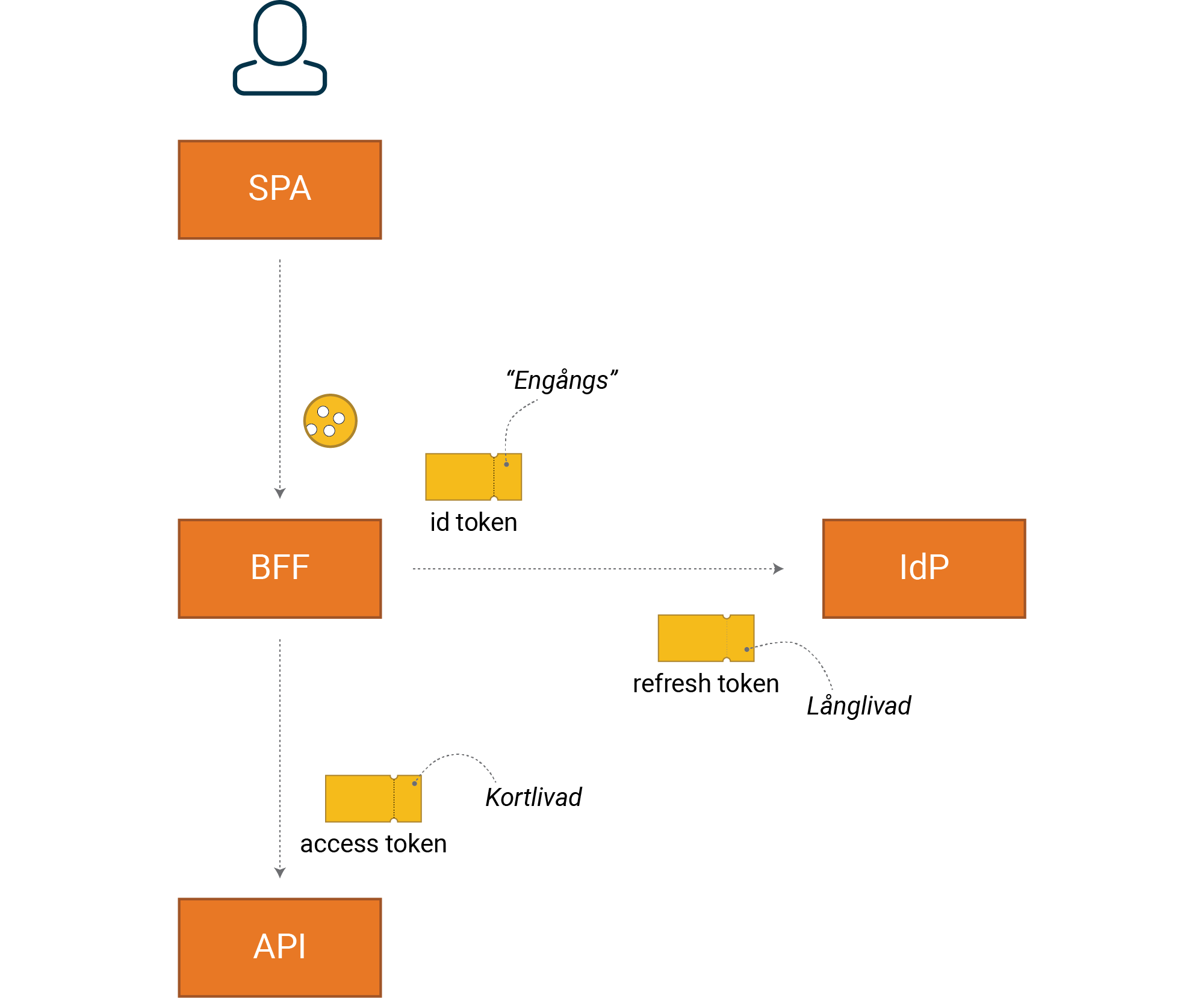 Eftersom HTTP är stateless och vi har webbläsare som frontend, så skapar vi
sessioner med cookies. Notera att alla tokens hanteras av BFF (backend), d v s
är ej tillgänglig för SPA (JavaScript i frontend).
Eftersom HTTP är stateless och vi har webbläsare som frontend, så skapar vi
sessioner med cookies. Notera att alla tokens hanteras av BFF (backend), d v s
är ej tillgänglig för SPA (JavaScript i frontend).
Id tokens är “engångstoken” för klienten, skickas ingenstans, och bör var giltiga kortast möjligt, i praktiken kanske 5 minuter. Tänk “authentication response”, inte token.
En Id token innehåller metadata från autentiseringstillfället, t ex vilken metod som användes, exakt tidpunkt etc. Till skillnad från access och refresh tokens så är id tokens specificerade genom OIDC. En id token innehåller också normalt lite information om användaren, som tex namn, men detta är inte huvudsyftet.
Kasper Karlsson, Omegapoint
Notera att en id token inte ska accepteras av ett API som en giltig access token – inte ens om den är en JWT. Detta är något som vi ibland stöter på i våra pentester.
Vår access tokens är ofta en JWT, eller en reference-token som kan översättas till en JWT. Den används av vårt API där den är grunden för vår behörighetskontroll av anrop.
Refresh token är en långlivad token som används för att hämta en ny, mer kortlivad access token från IdP. Det är inte en JWT utan en kryptografiskt säker slumpsträng.
Observera att refresh token flödet är en del av OAuth2, d v s det kan användas med eller utan OIDC och sessioner för att ge långlivad access för klienter som skall nå dina resurser även om du inte är aktiv.
Refresh token flödet fungerar enligt följande.
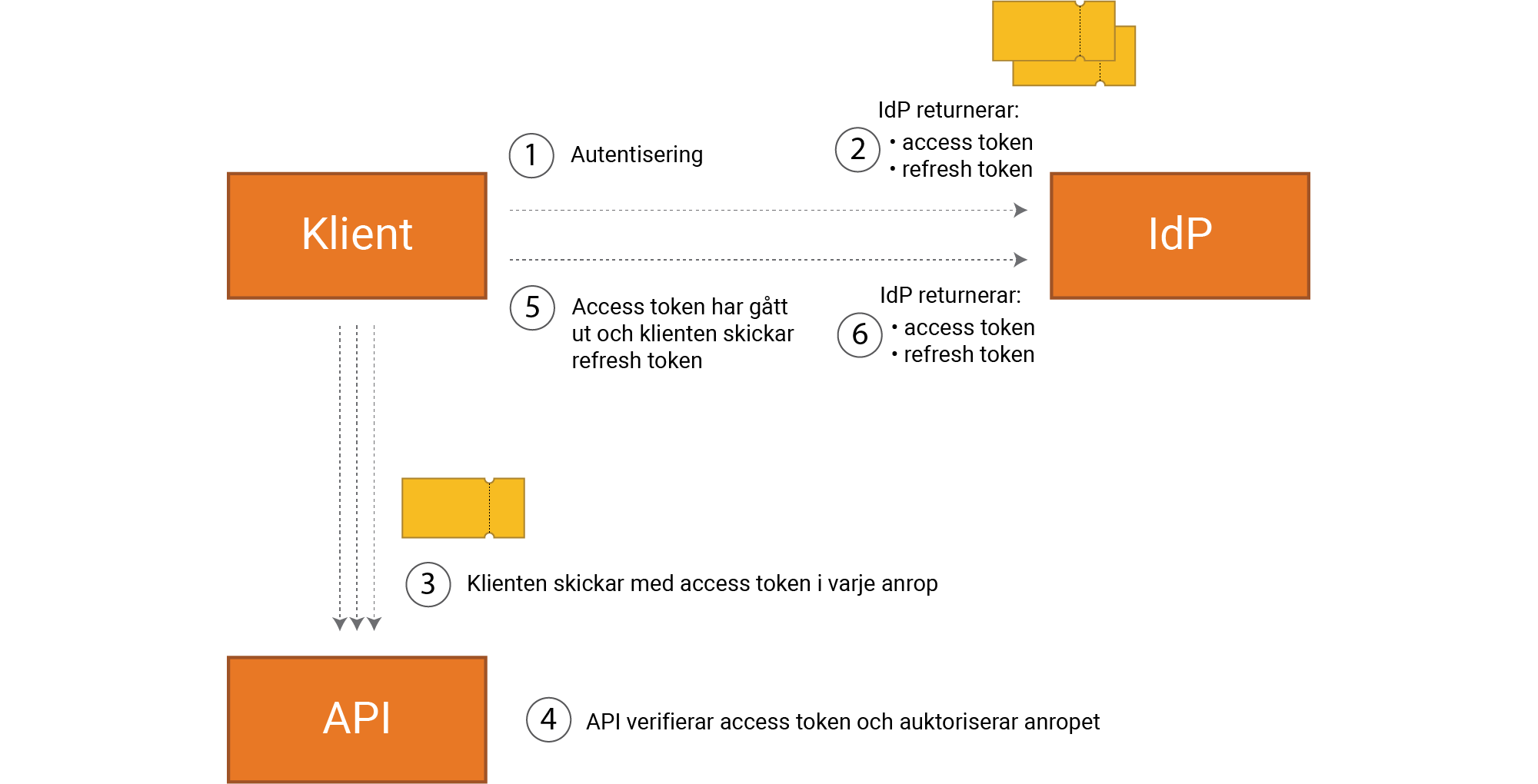 Notera att när en refresh token går ut så måste användaren återautentisera sig. Se mer på
https://datatracker.ietf.org/doc/html/draft-ietf-oauth-v2-1-02#section-6
Notera att när en refresh token går ut så måste användaren återautentisera sig. Se mer på
https://datatracker.ietf.org/doc/html/draft-ietf-oauth-v2-1-02#section-6
Nu står vi inför problemet att koppla dessa tokens till en användares session. Det är viktigt med kontroll över sessioner och en tydlig kravbild från verksamheten. Hur ofta användaren behöver autentisera sig är en viktig del av användarupplevelsen.
Tobias Ahnoff, Omegapoint
Vår erfarenhet är att många UX-avdelningar har fokus på tillgänglighet, och vill kanske helst inte ha någon inloggning alls. Men säkerhet är ju också konfidentialitet, integritet och ibland även spårbarhet. För t ex banker vill vi veta att användaren är närvarande och aktivt utför betalningar och t o m kan binda aktiviteter till dem i en juridisk mening. Här är det tydligt hur viktigt det är med rätt balans mellan samtliga säkerhetsaspekter för en komplett kravställning.
Med vår SPA som exempel får vi följande sessioner att hantera i en lösning med OIDC. Det är viktigt att förstå att cookie till BFF, tillsammans med cookie till IdP bildar en gemensam session till systemet för användaren. Här krävs det ett samspel mellan dessa båda cookies och livslängder på våra tokens.
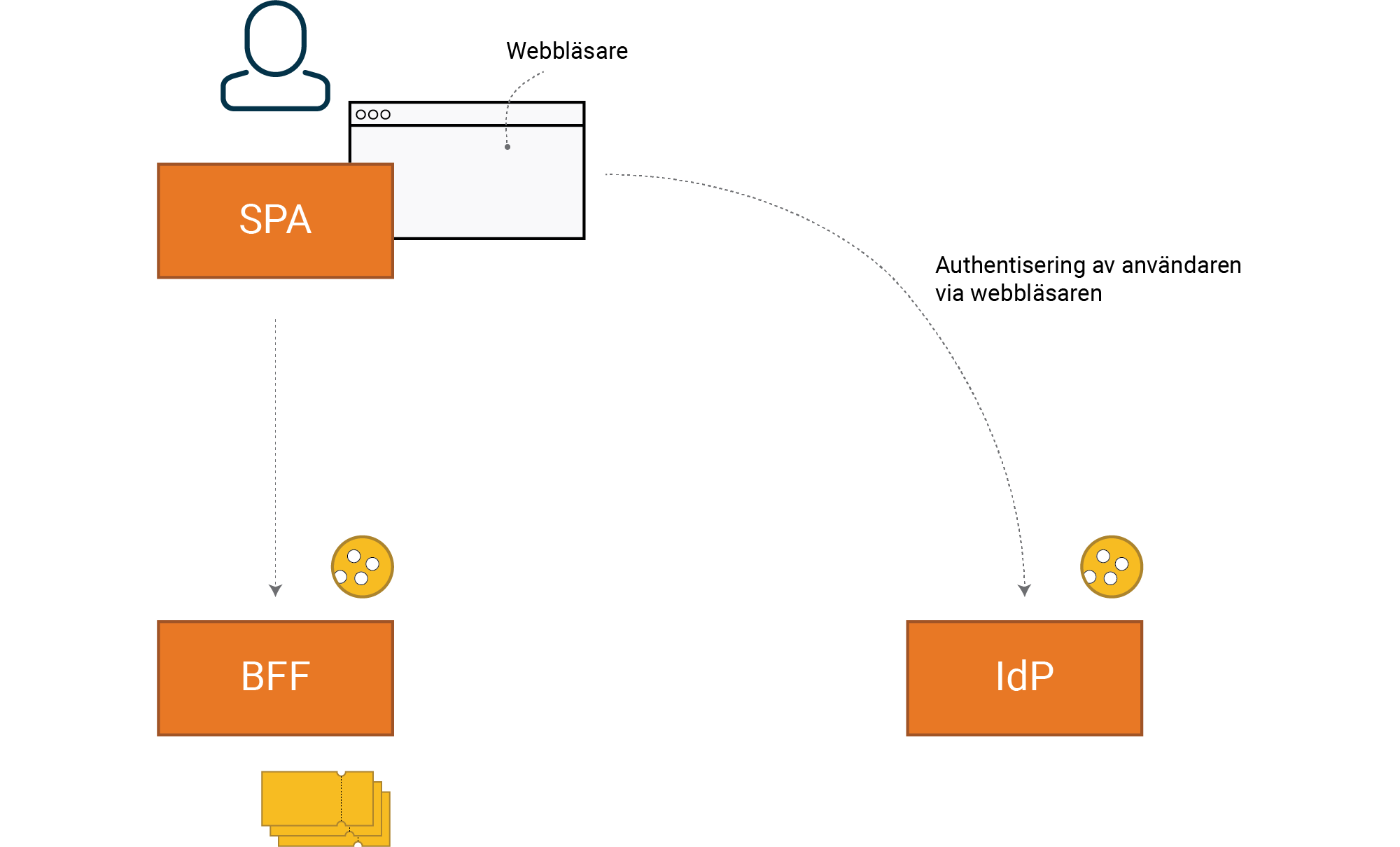 En OIDC-lösning ger två cookies och tre tokens att hålla koll på. Cookies är mellan
SPA och BFF, samt mellan SPA och IdP. Cookie mellan SPA och IdP ger oss Single
Sign-On, ofta kallad SSO-cookie.
En OIDC-lösning ger två cookies och tre tokens att hålla koll på. Cookies är mellan
SPA och BFF, samt mellan SPA och IdP. Cookie mellan SPA och IdP ger oss Single
Sign-On, ofta kallad SSO-cookie.
Livslängder för sessioner styrs i grunden av två parametrar:
- Inaktivitet, s k “Sliding Window”
- Maximal livslängd.
Kasper Karlsson, Omegapoint
Maxlängd är lätt att glömma, men spelar roll ur ett säkerhetsperspektiv. En angripare som lyckats stjäla en session kan annars nyttja den för evigt, även efter det att sårbarheten som möjliggjorde själva sessionsstölden har täppts till.
Hur ofta en användare måste autentisera sig beror väldigt mycket på din kravbild, en bank har kanske inaktivitet på 15 min och max på 60 min. En e-handel har inaktivitet i många veckor och kanske max i många månader. I exemplet vi visar har vi 7 dagar inaktivitet och 28 dagar max.
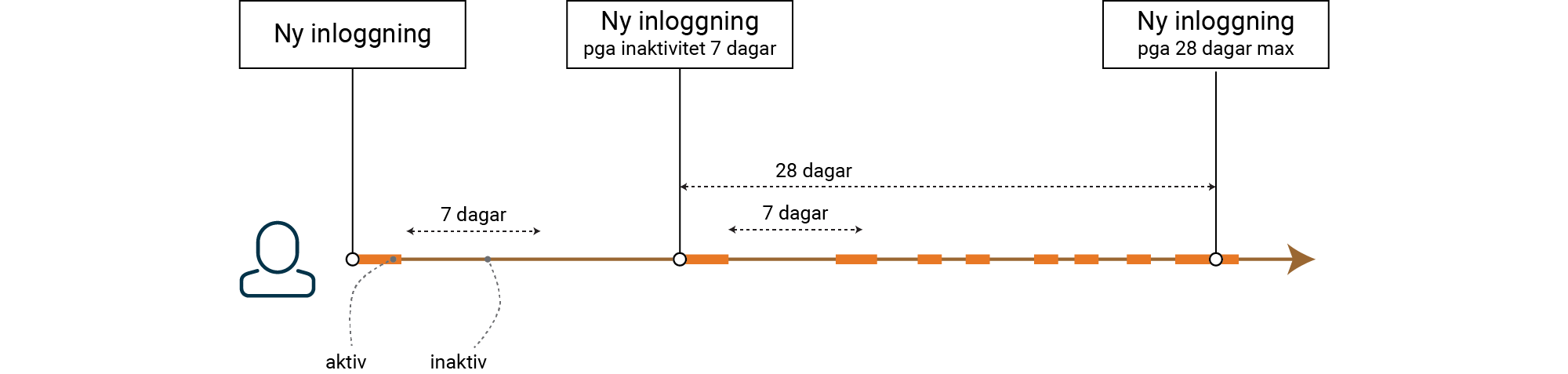
För att sessionen mot BFF skall fungera som förväntat, utan oväntad återautentisering, behöver klienten (BFF) ha tillgång till giltiga access tokens för användaren under hela sessionens livslängd.
Då access tokens är kortlivade krävs en giltighet för refresh tokens som är synkad med sessionen, I vårt exempel: 7 dagar sliding, med max på 28 dagar.
Access tokens skall alltid vara kortlivade, i vårt exempel kan man tänka sig t ex 60 min.
När sessionen är slut bör det inte finnas några aktiva tokens hos klienten, så tänk på att din sista access token kan gälla efter max för session och refresh token. Minuter spelar i praktiken oftast ingen roll, men dagar möter inte en kravbild där användaren förväntar sig att data endast kan nås av klienten under pågående session.
Målet för en session med höga säkerhetskrav är att vi kan lita på att användaren som autentiserat sig är närvarande under hela sessionen, inte bara vid inloggningstillfället. Så att vi också ger stöd för tillförlitlig spårbarhet.
Martin Altenstedt, Omegapoint
En klient som får en access token kommer ju att ha tillgång till mitt data under den tid som en access token gäller, oavsett om jag som person är kvar eller inte. Därför viktigt att kräva återautentisering vid extra känsliga operationer. Tänk signering av betalningar.
Vi vill lyfta fram vikten av tydlig kravställning kring sessioner, vilket ofta är något som missas och kanske lämnas till den utvecklare som implementerar. Följande konversation fångar många av de frågor som dyker upp när man implementerar SSO-lösningar.
PO – Vad händer när en BFF session tar slut och vi gör ett nytt anrop?
DEV – Då redirectas vi till IdP, och om vi då har en giltig SSO session behöver vi inte autentisera oss igen utan kommer tillbaka och kan direkt skapa en ny BFF session. Användaren kanske bara märker detta genom att det blinkar till i webbläsarens url-fält.
PO – Men om jag är hos IdP för att jag har varit inaktiv i 7 dagar, behöver jag inte autentisera mig igen?
DEV – Nej, det är riktigt, om din SSO session är längre än 7 dagar så behöver du inte autentisera dig igen
PO – Men då stämmer ju inte våra krav på hur vårt system ska bete sig? Min specifikation sa ju att man skulle kräva ny inloggning efter 7 dagars inaktivitet?
DEV – Just det, för att möta det, behöver vi ett samspel mellan SSO och den lokala sessionen mellan SPA och BFF. I ditt fall så behöver du en SSO session som har samma max och sliding som din BFF session.
PO – Men om jag inte är det enda systemet som använder IdP, och det finns fler system, med andra krav på inaktivitet och max längder på sessioner? Det kan ju vara väldigt olika krav mellan olika system.
DEV – Ja, det kan var problematiskt, olika IdP produkter ser olika ut här. En del tillåter att vi konfigurerar SSO session per klient, men andra produkter kanske inte gör det. Det samma gäller stödet för OIDC, där många stödjer det som definierats i Core-specifikationen, men kanske inte Session.
Erica Edholm, Omegapoint
Hur sessioner hanteras är kan vara svårt att testa och kanske något man ofta missar. Som alltid är det viktigt att komma ihåg de negativa testfallen och att säkerhet är ett av alla krav, t ex “Om jag som användare är inaktiv i X minuter behöver jag återautentisera mig” eller “När jag loggar ut blir jag utloggad i alla applikationer dit jag har SSO”. Automatiserad testning kring det här är svårt, ofta krävs manuell testning vilket ger långa ledtider och är tråkigt att upprepa :-)
Det är viktigt att reda ut sin kravbild kring sessioner och SSO, ytterligare krav tillkommer när vi i nästkommande avsnitt stärker skyddet kring sessioner och refresh-tokens, samt tittar närmare på logout och impersonering.
Val av IdP produkt är viktigt, så att den stödjer din kravbild, se mer på https://omegapoint.se/artikel-val-av-identity-provider-idp.
Säkra sessioner
För att stärka skyddet när vi använder cookies behöver vi tänka på ett par olika saker. Grundläggande är att vår session cookie endast skall innehålla information som är nödvändig för sessionen.
Kasper Karlsson, Omegapoint
Vi har sett sårbara system där känsliga sessionsdata lagras i “vanliga” cookies. En angripare har kunnat manipulera dessa för att exempelvis få åtkomst till andra användares konton, eller rentav byta roll och på så vis få utökade rättigheter i systemet.
De bör även vara kryptografiskt säkra, d v s antingen krypterad av BFF (backend) eller så behöver BFF ha en egen session store (Redis är vanligt) för att lagra din session. Din session cookie kan då istället endast innehålla ett kryptografiskt säkert id. Nackdelen är att du då introducerar state, en fördel är att du får en liten payload för dina anrop (som annars ofta behöver delas upp i flera cookies).
Vi bör även nyttja de skydd som webbläsare erbjuder i from av t ex HTTPOnly och Host-prefix “__Host-“, så att session cookies ej är tillgängliga för Javascript och tvingar säker användning av Domain, Path och Secure attributen.
Då vi använder cookies behöver vi också hantera Cross Site Request Forgery (CSRF). CSRF innebär att en angripare kan utnyttja din session till att utföra operationer som du inte är medveten om. Tex genom att du luras att klicka på en länk som du inte förstår är till vårt system. Detta fungerar eftersom webbläsaren automatiskt skickar med vår session cookie i varje request till BFF, vilket det gäller både läs och skrivoperationer.
Rekommenderade skydd från bland annat OWASP kan delas in i tre nivåer och vår erfarenhet är att följande tillsammans ger ett starkt CSRF-skydd:
- Webbläsare: SameSite Cookie policy Strict eller LAX
- Applikation: “Double submit cookie” mönster, eller motsvarande beroende på applikation och stöd i ramverk
- Användare: Återautentisering/signering för känsliga operationer (alt CAPTCHA-lösningar)
Även om SameSite har brett stöd, så gör olika webbläsare och versioner olika bedömningar om vad som är ok enligt Strict respektive LAX-policy. Och det är därför svårt att veta exakt hur det skyddet kommer fungera i praktiken för olika webbläsare över tid. Baserat på vår erfarenhet och OWASP rekommendationer bör vi därför se SameSite som ett komplement till andra skydd, t ex Double submit cookie.
Daniel Elmnäs, Omegapoint
Tänk också på tillgänglighetsaspekten av säkerhet. Ett problem som flera av oss som jobbat OIDC de senaste åren stött på är att inloggningar misslyckas på grund av ändrad implementation av cookie policies i webbläsare. Detta kan vara svårt att felsöka och övervaka och kanske mycket allvarligt för din verksamhet.
Oavsett övriga CSRF-skydd så är stark återautentisering ett måste för mycket känsliga operationer där vi har krav på spårbarhet.
Björn Larsson, Omegapoint
Kom ihåg att XSS i praktiken går förbi i princip alla skydd kring vår session, utom kanske just stark återautentisering, så prioritera alltid skydd mot XSS när du bygger webbapplikationer och bygg säkerhet i flera lager, med försvar på djupet!
Säkra refresh tokens
Refresh tokens är mycket känslig information och bör därför hållas backend, i en miljö vi kontrollerar fullt ut. De bör alltså ej vara tillgängliga i browsers där man kan nå dem via JavaScript, vid t ex en XSS-attack.
Ett annat grundläggande skydd för refresh tokens är att de skall vara bundna till klienten.
För konfidentiella klienter, en back-end som vi kontrollerar (t ex en BFF), gör man det genom klientautentisering varje gång som man förnyar en refresh token.
För system med höga säkerhetskrav bör alla klienter vara konfidentiella. Om vi har publika klienter bör vi undvika långlivade refresh tokens för dessa klienter. Men det är en bedömning som behöver göras beroende på din kravbild och riskanalys.
Tobias Ahnoff, Omegapoint
En vanlig problematik är mobilappar, som är publika (native) klienter med behov av långlivad access. Ofta görs bedömningen att risken med refresh tokens för dessa är acceptabla. Förutsätt att man gör det man kan för att skydda dem genom säker lagring, hantering och rotering av tokens. Notera att OIDC CIBA är på väg att etableras och kan vara ett sätt att hantera problemet då det, precis som en BFF, för med sig en konfidentiell (backend) klient även för mobilappar.
För att stärka skyddet är det rekommenderat genom OAuth 2.1 att refresh tokens bör var engångs, d v s roteras på varje refresh token request, och att det bör finnas “misuse detection”.
Att upptäcka missbruk är dock lättare sagt än gjort. En IdP har i praktiken mycket svårt att avgöra om någon för en publik klient stulit en token och använder den enligt ett normalt mönster. En konfidentiell klient däremot, med en session, har bättre möjligheter då klienten kan nyttja sin domänkunskap om vad som är ett rimligt användarmönster och kan göra en djupare analys.
Vi vill också än en gång poängtera att du för webbapplikationer bör prioritera skydd mot XSS. Du kan ha gjort allting rätt med hur tokens och sessioner hanteras, men om du har en XSS-sårbarhet så kan en angripare gå förbi i princip alla dessa skydd.
Kasper Karlsson, Omegapoint
Vid penetrationstester av webbaserade system hittar vi nästan alltid XSS-sårbarheter. En angripare kan använda sådana sårbarheter för att stjäla tokens – långlivade refresh tokens kan till exempel vara av stort värde för angriparen.
Vi återkommer till XSS och skydd för det i artikeln om Webbläsare på https://omegapoint.se/forsvar-pa-djupet-webblsare-del-6-av-7.
Single logout
För ett säkert system och en bra användarupplevelse är det viktigt att användaren kan avsluta sin session på ett kontrollerat sätt. Vi kan dock inte förutsätta att användare loggar ut och basera vår säkerhet på det. Däremot är det vårt ansvar som klient att städa ordentligt för en användare som aktivt loggar ut.
I en OIDC-lösning med SSO krävs dels lokal utloggning (1), men också utloggning mot IdP (2).
Vill man ha Single Logout (3) så krävs även utloggning mot övriga klienter som har SSO (mot samma IdP). Vilket då görs med OIDC Back-channel logout, där IdP notifierar alla andra klienter som registrerats för Single-logout.
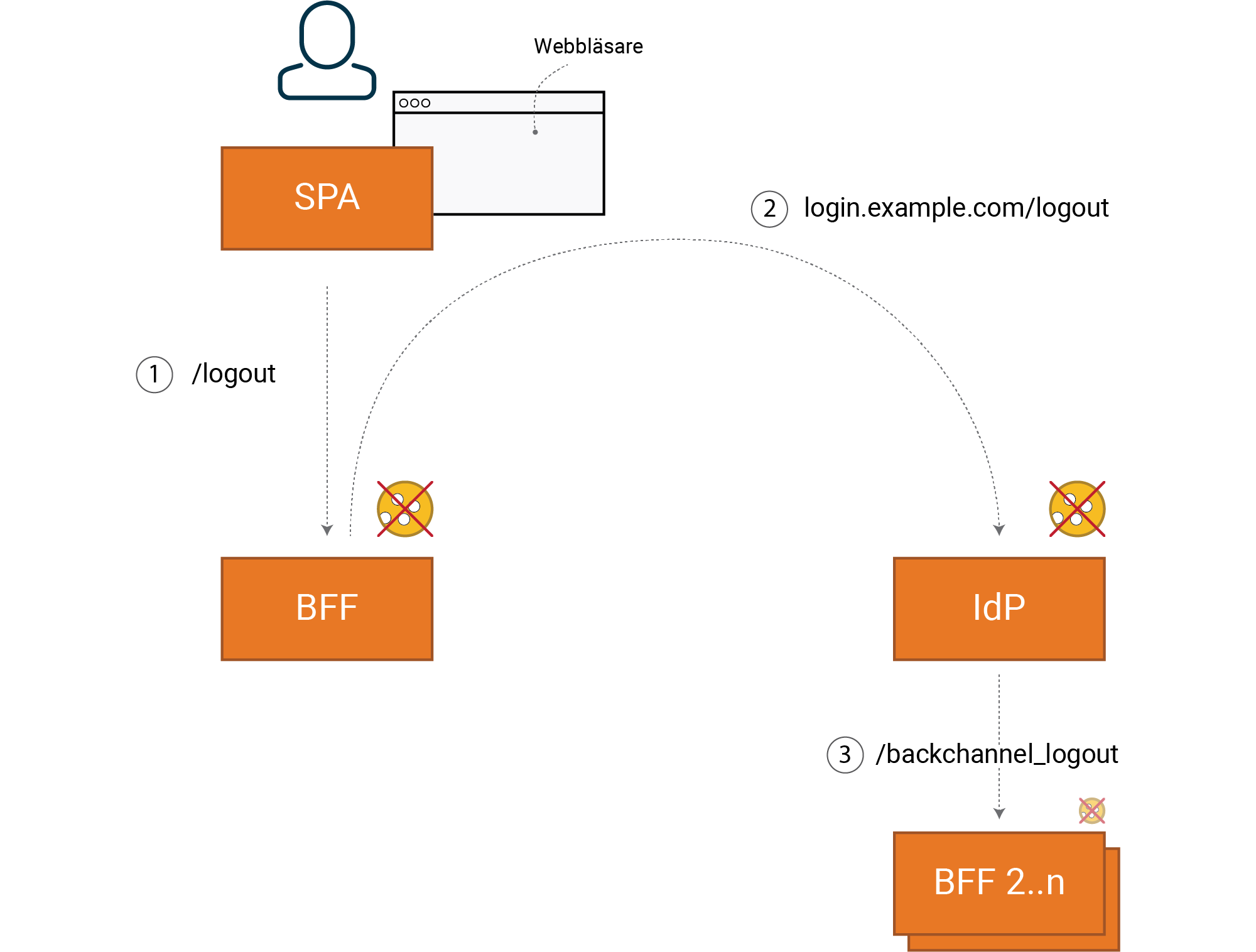
Notera att steg 3 kräver att klienten (BFF) håller sessionens tillstånd backend, via t ex en Redis Cache. Men även om vi inte behöver Single logout så behöver vi hålla sessionens tillstånd backend för att ha full kontroll över våra sessioner, det beror dock på dina systemkrav om det är motiverat eller ej att införa state-beroende.
Martin Altenstedt, Omegapoint
En fråga vi ofta får är hur man som administratör loggar ut någon annan eller låser ett konto? När vi har total kontroll över våra sessioner genom att vi hanterar state backend, kan vi helt enkelt kan radera användarens session i vår BFF och IdP och trigga en Single Logout.
Tobias Ahnoff
SSO är lätt, Single Logout är svårt. Att få en bra konsekvent användarupplevelse kräver ofta mer än man tror, här finns det t ex risk att val av IdP kan begränsa dig i vad som är möjligt i samband med utloggning.
Om alla sessioner skall bete sig som en session kanske man skall fundera på om det skall vara en applikation och en lokal session så man undviker Single Logout problematiken. “Complexity is the worst enemy of security” är värd att läsa! Du kan inte säkra det du inte förstår :-)
Impersonering
I många system har vi ett behov av att agera som någon annan. Det kan tex vara i kundsupport om vi vill logga in som en användare och se vad hon ser, eller om vi vill utföra en arbetsuppgift åt henne.
För detta finns ett flöde som benämns “token exchange”, vilket innebär att vi byter ut vår egen token mot en ny, men utan att tappa vem som agerar.
I vårt exempel har “admin” autentiserat sig via t ex ett Code-flöde så att klienten har en giltig access token för “admin”.
Klienten erbjuder ett gränssnitt så att “admin” kan välja vem som skall impersoneras, i det här exemplet är det “user”. Klienten anropar token-exchange endpoint och skickar med access token för “admin”, samt “user” som är målet för impersonering (1).
IdP behöver nu göra en behörighetskontroll, för att avgöra om “admin” får göra impersonering. Därefter returnerar IdP en ny access token där sub är “user” och ett act-claim med sub “admin” (2).

{
"aud":"https://api.example.com",
"iss":"https://issuer.example.com",
"exp":1443904177,
"nbf":1443904077,
"sub":"user@example.com",
"act": {
"sub":"admin@example.com"
}
}
Notera att ett API nu kan auditlogga att det är “admin” som är källan till operationen, även om den utförs med samma behörigheter som “user”.
I specifikationen (https://datatracker.ietf.org/doc/html/rfc8693) benämns detta som delegation. Till skillnad från impersonation där man inte kan avgöra vem som agerar, som blir fallet i det här exemplet om man inte har med act-claimet.
Olika IdP produkter skiljer sig åt i hur man stödjer detta och liknande scenarier, kolla din produktdokumentation för att se hur det fungerar för din lösning.
Summering
De tre första artiklar ger dig vad du behöver för att kunna bygga en stark och finmaskig behörighetskontroll för vårt system.
I den första artikeln gick vi igenom hur vi kan modellera identitet med hjälp av de koncept och verktyg som OAuth2 och OpenID Connect ger oss.
Artikel 2 diskuterad hur vi bör tänka när vi bestämmer oss för vilken information som bör finnas i vår access token, och hur vi går från token till rättigheter och behörighetskontroll i våra API.
I denna artikeln har vi gått igenom hur vi får tag på en access token för olika typer av klienter och hur vi hanterar våra sessioner, samt SSO och Single logout.
Nästa artikel beskriver vad du behöver för att bygga ett säkert API med en stark behörighetskontroll.
Se Defense in Depth för ytterligare material och kodexempel kopplade till den här artikelserien.
Fler artiklar i serien:
- Försvar på djupet: Del 1 Modellering av identitet
- Försvar på djupet: Del 2 Claimsbaserad behörighetskontroll
- Försvar på djupet: Del 3 Klienter och sessioner
- Försvar på djupet: Del 4 Säkra API:er
- Försvar på djupet: Del 5 Infrastruktur och lagring av data
- Försvar på djupet: Del 6 Webbläsare
- Försvar på djupet: Del 7 Sammanfattning