Defense in Depth: Secure Architecture
6 November 2025Envision a system that shares data that should be available only to the correct and authenticated users over a public network. We often also want to differentiate between different types of users and give these users access to different types of information. A user should not be able to gain access to data or functionality that does not match her permissions. We also need to protect our systems against targeted external attacks.
We believe that the following three architectural principles drive all other security aspects in architecture decisions for a secure implementation under these circumstances:
- Zero Trust
- Least Privilege
- Confidentiality, Integrity, and Availability (CIA)
Since the context of this article is application development, we define Zero Trust as:
- All networks considered insecure
- All clients and users authenticated
- Access control for every request
And we define Least Privilege as:
- Limit access to a bare minimum for all actors
By CIA, we mean that security is a balance between confidentiality, integrity, and availability. We often also add accountability to this triad.
If you follow these three principles, it will affect all form of architecture that is related to development, maintenance, and operation of any IT system.
Case study
We will apply these architectural security principles to an example system that supports many scenarios that we often encounter in our work.
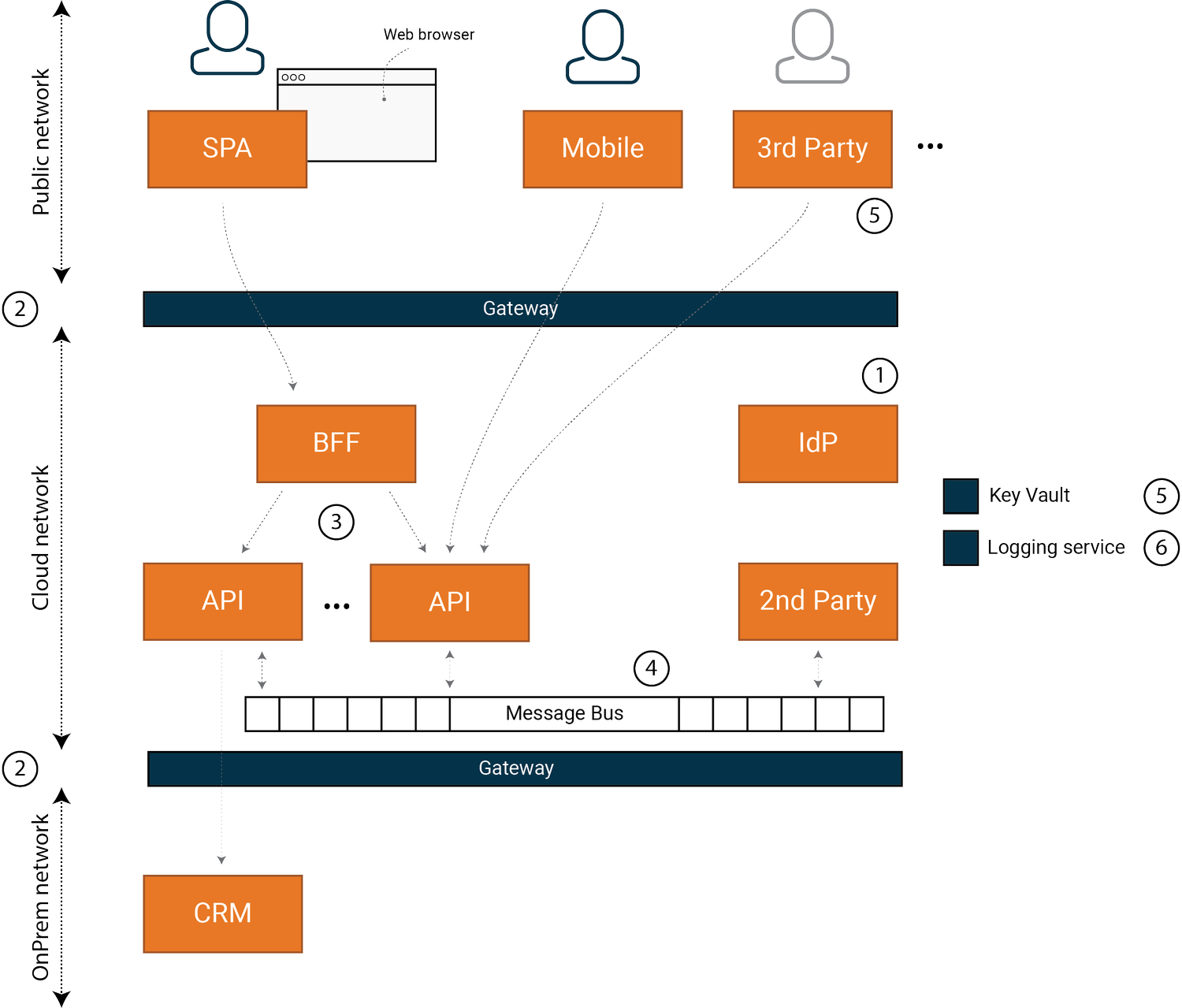 Figure 1: System in this case study
Figure 1: System in this case study
The example system has a set of user types, that each have different access to the system. Role-based systems are common. For example, we might define and manage roles in Microsoft Active Directory. Often, there is more than one source of users; we might complement an AD instance with a local database or integrate with another system.
The system contains a set of first-party clients that are implemented, operated, and maintained by the organization. The system also serves data to a set of clients from third parties.
The system has a set of APIs that are hosted on a cloud platform and a set of on-premises APIs and systems that are hosted in an internal network. The internal network cannot be reached from the outside network, but the internal network can reach outside networks.
The set of APIs that are hosted on the cloud platform includes a set of services that are closer to the organization than the third-party clients, but not fully integrated in the organization. It can be partners, or more independent parts of the organization. We label these as “second-party” components.
Finally, we have a central token service, or Identity Provider (IdP) that is the single source of truth for identity. Today, the protocol is OAuth2/OIDC, but the same concept has been around for many years under different protocols, like SAML under the SOAP era.
Pontus Hanssen & Tobias Ahnoff, Omegapoint
The current best practices for OAuth2/OIDC state that tokens should not be handled in JavaScript frontends. Developers should instead opt for the Backend For Frontend (BFF) pattern with a confidential OAuth2 client. To learn more about this pattern and possible pitfalls to be aware of, see our talk from Security Fest 2023 — How to f*ck up at OAuth2 while following BCPs.
For this context, we want to highlight six important architectural decisions and patterns that fundamentally impact the overall security of this system.
1. Identity and authentication
The industry standard for token-based access control today is OAuth2. It is a well-known protocol with a rich set of best-practice documentation for a wide range of requirements, from the simplest to financial grade systems.
The starting point for any secure system is to model scopes and resources using the concepts in OAuth2. See the articles Identity Modeling and Claims-based access control for an in-depth description of what such a model can entail.
You also need to select an IdP product. There are many choices on the market today. See the article How to choose an IdP for a detailed discussion on what you need to consider. For this article, we will assume that the IdP supports all things we need, like MFA, integration with AD, etc.
2. Network
Transport layer protection is key to a secure system. An attacker that can intercept traffic in a system that uses OAuth2 will typically be able to gain complete access, over time. End-to-end TLS from the client to the API is ideal but sometimes not practical.
Common relaxations of end-to-end encryption are:
- Termination and re-encryption at the gateway
- Termination at the gateway and unprotected internal traffic
You need to balance the convenience of unprotected traffic against the risk of an attacker in the network. A larger network shared between several systems and teams requires transport layer protection. We might, for example, accept the risk of unprotected traffic in a well-managed Kubernetes cluster if the number of people with access to the cluster is small and limited to a single team.
For a more detailed discussion, see the article Infrastructure and data protection.
3. “Chained” authorization
We sometimes need to make chained network calls to another API in our system. This pattern is more prominent the more and the smaller the APIs are. For the request/response interaction model, there are a few options:
- Pass the original token to the second API
- Create a new token in the first API
- Exchange the original token for a new token using OAuth2 Token Exchange
The option to pass the original token to the second API is obvious and works well. The downside is that the scope of the original token might not be suited for the second API.
The second option mitigates this problem, but we might lose accountability of the origin of the call. There is also an overhead that the first API needs to be a registered client with the IdP.
The third option means we keep full accountability, but all IdP products do not support it. There is also an added complexity at the second API to look deeper into the access token to extract the call chain for tracing.
We want to recommend against moving from a token to another means of access control; for example, to an API key or IP-based security for chained, internal network calls. This pattern typically leads to violations of the least privilege principle. Also, multiple authorization methods in the API increase complexity and make it harder to keep a system secure over time.
For more on token based authorization, OAuth2 and OIDC patterns, see the articles Claims-based access control and Clients and sessions.
4. Trust boundaries
A trust boundary is a boundary in our system where data is assumed to be trustworthy.
Architecturally, we establish patterns of communication between trust boundaries. From a security perspective, the selection of communication patterns can greatly impact your trust boundaries. Two patterns are common:
- Requests/response (HTTP)
- Event stream (message bus)
Request/response is a well-established pattern from a security perspective. Under this pattern, an API typically represents a trust boundary if it has strong access control and well-defined contracts.
The event stream pattern is more challenging from a trust boundary perspective. We identify the following patterns for sending and receiving messages:
- Shared bus, topic, or queue
- Separate buses, topics, or queues
- Signed individual messages
In a shared scenario, clients send and receive messages without any ability to verify message identity or origin. Lack of identity and origin means it is impossible to implement access control at the receiver. The security effect of this pattern depends on the number of clients and what functionality the messages represent. We often overlook that this can lead to a trust boundary that is much larger than intended.
We can narrow the trust boundary by maintaining unique client authentication to separate buses, topics, and queues. The effectiveness of this pattern depends on the number of clients on each bus, topic, and queue.
Signing individual messages is an alternative pattern to control the trust boundary when multiple clients use the same channel. We use identity and origin for each message to implement access control in the receiver. The downside is that we need to maintain asymmetric keys between producers and consumers.
For a detailed discussion and how to implement trust boundaries for an API, see the articles Secure APIs, Secure APIs by design and Test Driven AppSec.
5. Secrets
Third-party systems integrate with our API in the same way that clients do. All third-party clients need to be registered and managed in our IdP.
Managing shared secrets in the system requires using a component that is built to store and access secrets. A strong pattern in a cloud environment is to use a dedicated vault service from the cloud provider. Rotating client secrets on a recurring schedule is an essential and often overlooked aspect of integrations. Another challenge we often encounter is how a shared secret is communicated to the third-party.
When our system acts as a client to an external system, then the rules of that system apply.
See the article Secure APIs by design section Secrets — support Rotate for discussion and code samples regarding secrets.
6. Logging and monitoring
For a secure system, it is important to have full visibility into how the system works, part of which involves having a clear and consistent approach to managing and logging errors.
Logging errors and activities centrally in the system is fundamental for detecting intrusions and providing accountability.
There are a lot of good, centralized logging products. One important feature that some products offer is anomaly detection and alerts.
See logging sections in the articles Secure APIs, Secure APIs by design and Test Driven AppSec. The code linked from these articles shows how secure error handling and logging can be implemented for an API, see Defense in depth .NET and Defense in depth Java for code samples.
Further reading
Secure architecture is a broad topic. This article highlights six important architectural decisions and patterns that fundamentally impact the overall security of this system. The article is also provides an overview and introduction to the seven part article series Defense in depth.
See Defense in Depth for additional reading materials and code examples.