Defense in Depth: Clients and sessions (part 3/7)
6 November 2025In the first two articles, we discussed how to design your system in order to build strong access control. We looked at how you can strike the right balance in terms of what information is associated with your access token, and we looked at balancing identity and local permissions. This article will take a look at how to configure a client in order to get a token, and how we handle sessions.
Let’s start by separating our clients into their different types:
- Service integration (machine-to-machine)
- Web (both SPA and server-side)
- Native (iOS, Android, Windows, Linux, macOS etc)
- Devices (client without browser or with limited ability to enter a password, e.g. TV and terminals)
Today, from the OAuth2 spec, we only need to pick out three different flows which cover all client types.
- Client Credentials (Service integration)
- Code+PKCE (Web and Native)
- Device Code (Devices)
Client Credentials represent a client where no human is involved, e.g. another service or automated job.
Code+PKCE is used for all clients that are used by a human and which have a web browser.
Device Code is used if the client does not have a web browser, or if the user has limited ability to enter text. Examples are TVs, terminals (CLI) etc.
Martin Altenstedt, Omegapoint
The fact that we have “only” three flows is a major simplification compared to a few years ago and makes them a lot easier for me to work with. I really do recommend that you read up a bit on these three flows if you’re in charge of identity and login. https://oauth.net/2.1/ is a good place to start for more info on best current practicves for OAuth.
Service integration
Clients where no human is involved are an important component in more complex systems. The systems being built today are increasingly comprised of loosely connected services. Communication between these services creates a need for this type of integration. Another example is automated system testing on operational systems. The process that runs the tests in the pipelines for continuous integration (CD/CI) is a client of this type.
These clients often represent a privileged user who has extensive rights in the system. It’s important that our permissions model and scopes are good enough to be able to restrict rights for this client type. System test clients, in particular, are problematic since they need access to the entire system.
Erica Edholm, Omegapoint
I often see test clients with full system privilege, which is a problem when client secrets are being handled inadequately.
We also lose a huge amount of test cases when we have a test client that has rights to everything. It’s better to have multiple test clients with more specialized system permissions.
What’s even worse is turning off parts or even all of your access control for systems undergoing testing! Not only can this setting find its way into production, but you’re not actually testing the code that will go into production.
We when design our system, we need to think about testability :-)
The flow we use is called “Client Credentials” and it’s the simplest of our three OAuth2 flows.
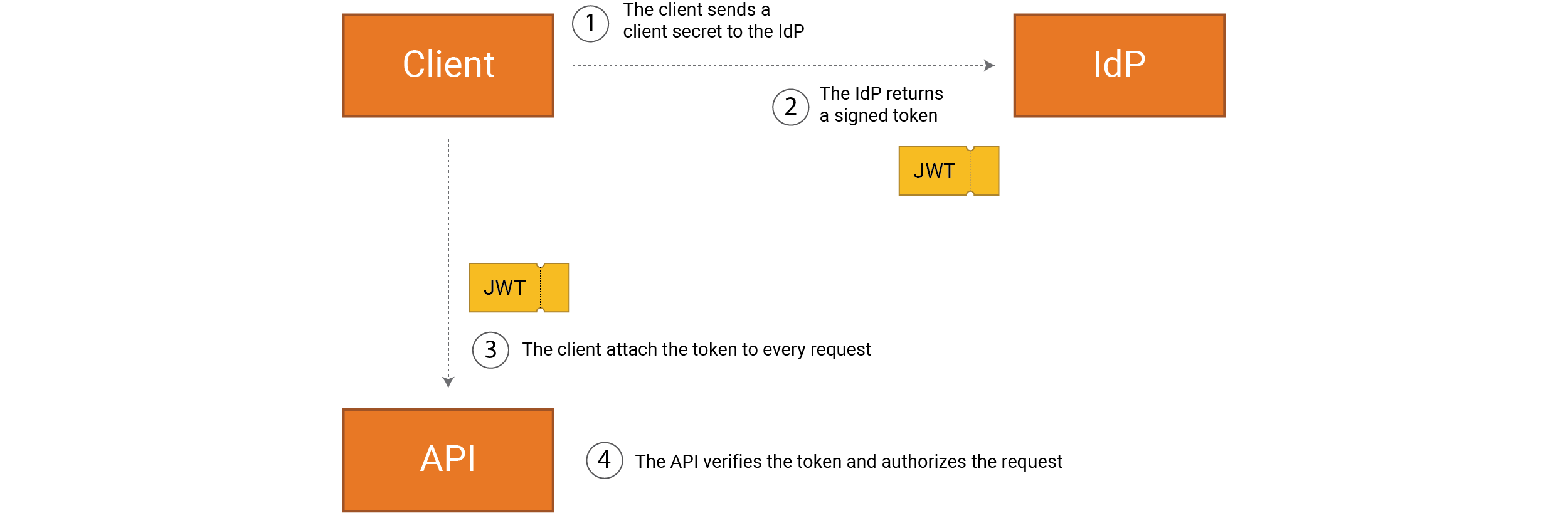 The client authenticates itself by presenting its client credentials and receives an access
token (e.g. a JWT) that can be used for subsequent API requests.
The client authenticates itself by presenting its client credentials and receives an access
token (e.g. a JWT) that can be used for subsequent API requests.
The way the client authenticates itself is by using a client secret or a public-private key pair (i.e. a X.509 certificate using mutual TLS or a JWT using “Private Key JWT”). A crucial aspect of client secrets is that they are machine-generated with a high degree of entropy. As they are cryptographically secure (unique and non-guessable), they don’t suffer the same weaknesses as a password chosen by a human.
If we choose to have our client authenticate itself using mutual TLS (mTLS) then we can increase security by using sender-constrained tokens, where each API verifies that the client’s access token is associated with the clients certificate. It can therefore only be used by a client with access to the certificate’s private key, as opposed to an access token that is not sender-constrained and can be used by anyone who has the (bearer) token.
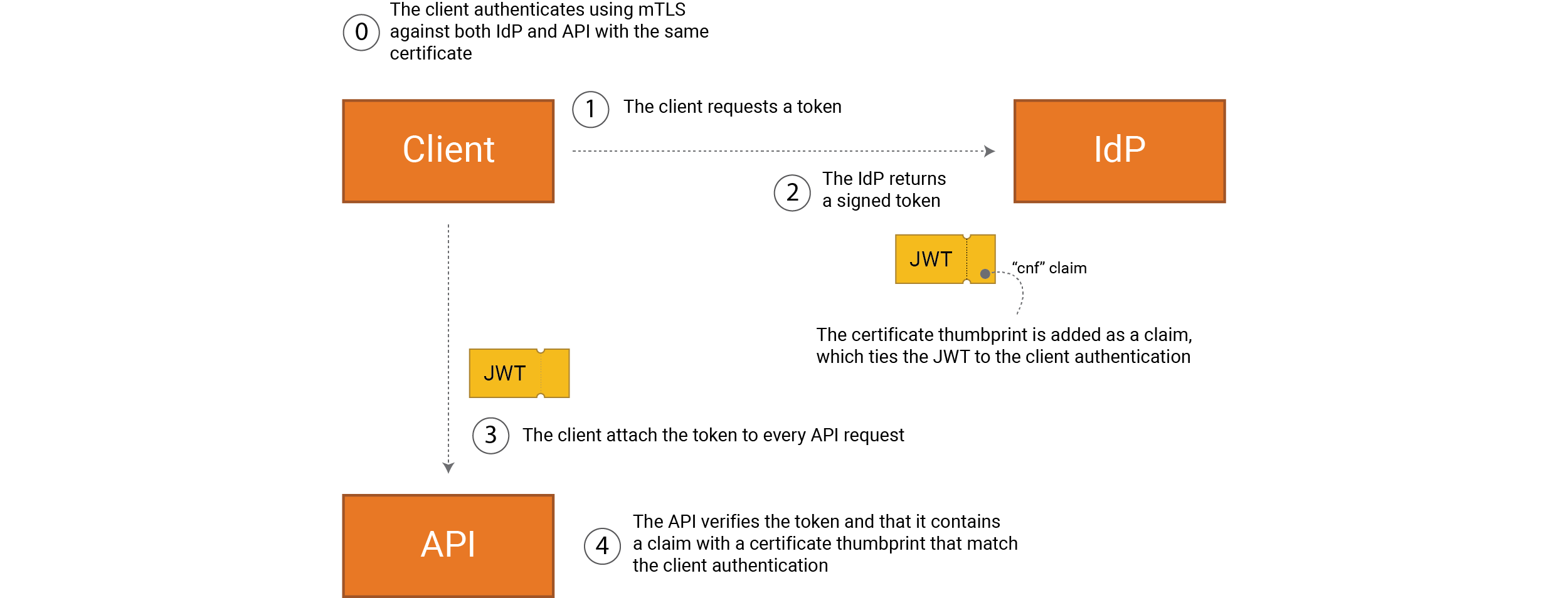 If the client uses mTLS the information on the client’s certificate thumbprint will be added in the cnf claim.
If the client uses mTLS the information on the client’s certificate thumbprint will be added in the cnf claim.
APIs can then use this information to ensure that the access token is sent from the same client (the client that has access to the private key). This means that an attacker will be unable to send a stolen access token from a different client.
The downside of this is that we need to manage client certificates, which can be a more complex operation compared to handling client secrets.
Note that we can still bind tokens to a client without having to manage certificates by generating certificates on the client per session. We only use these certificates to associate a token with the client via mTLS. In this case, we don’t use the certificate to authenticate the client in the OAuth2 flow.
Miranda Aldrin, Omegapoint
Another way to bind the access token is to use OAuth 2.0 Demonstrating Proof-of-Possesion (DPoP). This is relatively new, but gaining support in authorization servers. More details on DPoP can be found at https://oauth.net/2/dpop.
It’s also important to note that you need to rotate credentials used for client authentication, this applies to both private-public key pairs and client secrets. Rotating credentials and secure mangement can in practice prove to be a major challenge for an organization.
Martin Altenstedt, Omegapoint
A common problem is that client secrets for system clients are not handled in a secure way. They might be checked in together with the client’s source code, for example, or sent over via email, text or chat. Combined with the fact that they represent privileged access to the system, this can constitute a serious security flaw.
Another issue is that secrets are not rotated, which increases the risk that a former employee or attacker can gain access to the system. It’s important that you design your systems in such a way that rotating secrets on a recurring basis is easy.
The same applies to certificates. However, they are often are a part of PKI processes and therefore manged in a more secure way than client secrets.
In order to increase protection even more, we can also make use of reference tokens as access tokens instead of a full JWT.
A JWT contains all the information our API needs to conduct access control. The problem with a JWT is that it can’t be revoked, and that it often contains personal data. This is extra important if the client represents a privileged user, if it is developed by a third party or is public.
We should consider strengthening the protection for service integrations further using reference tokens instead of a JWT. As always, it’s about striking a balance between security and system performance.
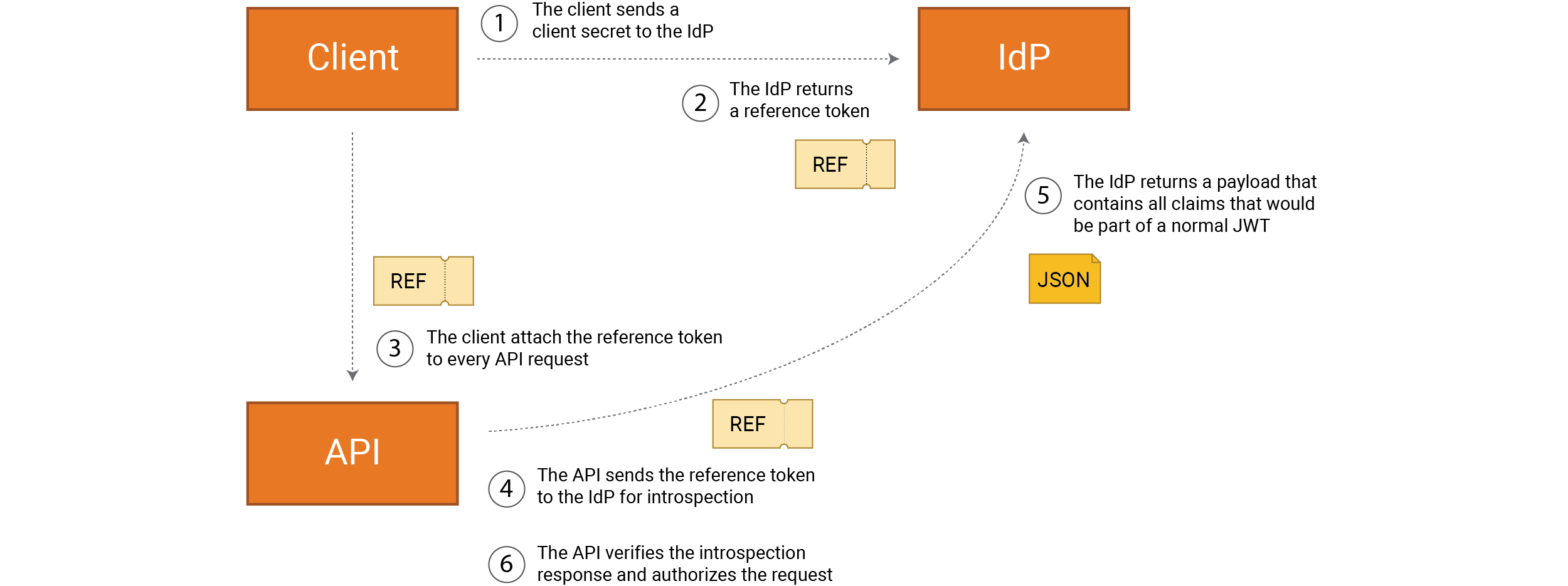
A reference token does not contain any information and offers stronger protection compared to a full JWT, since it can be canceled immediately. The downside is you need an extra request from API to IdP in order to look up a full JWT with each request.
Now we’ve established a foundation that we can use in all our flows. We can strengthen our protection by using a few different patterns:
- Mutual TLS (mTLS) or Private Key JWT instead of Client Secret
- Sender-constrained access tokens, using either mTLS or DPoP, instead of bearer tokens
- Reference token instead of a self-contained access token (JWT)
For more details on high security OAuth (and OIDC) see https://oauth.net/fapi
Tobias Ahnoff, Omegapoint
Even if a client has access to several scopes, we need to remember to use as few scopes as possible. This is particularly important whenever tokens are sent to third-party services you don’t control. When not using sender-constrained tokens, what prevents the service from using your token with other services? The principle of “Least Privilege” also applies to tokens. This is explained further in my talk Secure System Integrations at NDC Security 2025.
Web
Regardless of if it is a Single Page Application (SPA) or server-rendered HTML, the Code+PKCE flow is applied. From now on we will discuss SPAs. Based on our experience, this is the most common way to build web applications today.
The recommendation from IETF is to use a Backend For Frontend (BFF) as a client to the IdP. With this pattern the SPA frontend will only talk to the BFF, which act as a proxy to all other backend APIs. The SPA use cookie authentication for the BFF. The BFF will attach an access token connected to the users session to backend API requests. Thus, the BFFs responsibility is to assert that the right token is used for the right backend API request.
Integrating directly from the web client to the IdP using oidc-client-js, auth0-js or similar libraries is more problematic. As web browsers increase privacy protections for user data, our technical possibilities for building a good solution using these libraries are becoming limited.
https://datatracker.ietf.org/doc/html/draft-ietf-oauth-browser-based-apps#section-6
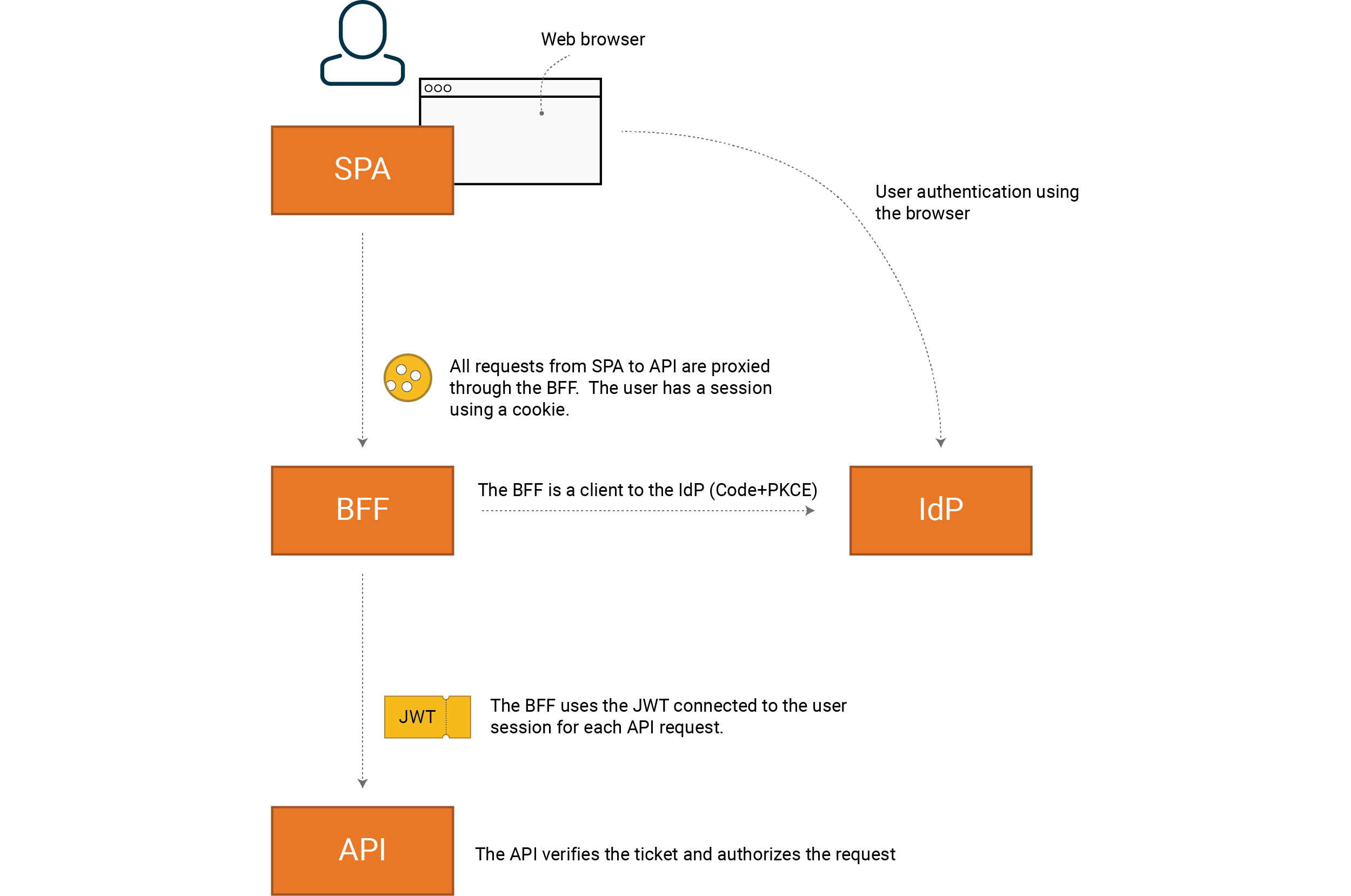 The client with respect to the IdP is the BFF, not our SPA. The correct flow for
integration with IdP is Code+PKCE.
The client with respect to the IdP is the BFF, not our SPA. The correct flow for
integration with IdP is Code+PKCE.
Note that you can strengthen your protection using reference tokens and sender-constrained tokens following the same pattern that we described in the previous chapter on service integration. Compared to direct integration between SPA and IdP, a BFF gives us the possibility of very strong protection since tokens are only handled in an environment we control (backend).
Use a framework that gives you a good basis for building a BFF. For security-critical functions, we want to base our solutions on robust components, well-established patterns and reference implementations. Security is, quite simply, an area where you should avoid coming up with your own solutions.
Pontus Hanssen & Tobias Ahnoff, Omegapoint
The current best practices for OAuth2/OIDC state that tokens should not be handled in JavaScript frontends. Developers should instead opt for the Backend For Frontend (BFF) pattern with a confidential OAuth2 client. To learn more about this pattern and possible pitfalls to be aware of, see our talk from Security Fest 2023 — How to f*ck up at OAuth2 while following BCPs.
See the section below on Sessions for more information on how we need to handle cookies and tokens for the user to be able to use the application over an extended period.
Native
Examples of native clients are mobile apps on iOS and Android, as well as programs installed on Windows, macOS and Linux. Formally speaking, we mean a client that is public, that can be deconstructed by an attacker. Compare this to a confidential client, such as our BFF, which an attacker does not have access to and which we can therefore entrust secrets to. Many native clients have good capabilities for storing a secret but with one crucial caveat.
Even if a platform such as iOS has the capability to store a secret in a cryptographically secure manner, an attacker who has access to the environment where the client is being run can still extract secrets directly from the client memory. Different platforms have different levels of protection but that’s why there’s good reason to use reference tokens since, unlike a full JWT, since they never contain any personal data and can be canceled immediately.
The flow the client should use is Code+PKCE. We use the system’s web browser for authentication with respect to the IdP. As always, we should use readymade libraries for integration with IdP. All major platforms have this type of readymade library. Choose the one that has the best support for your particular scenario.
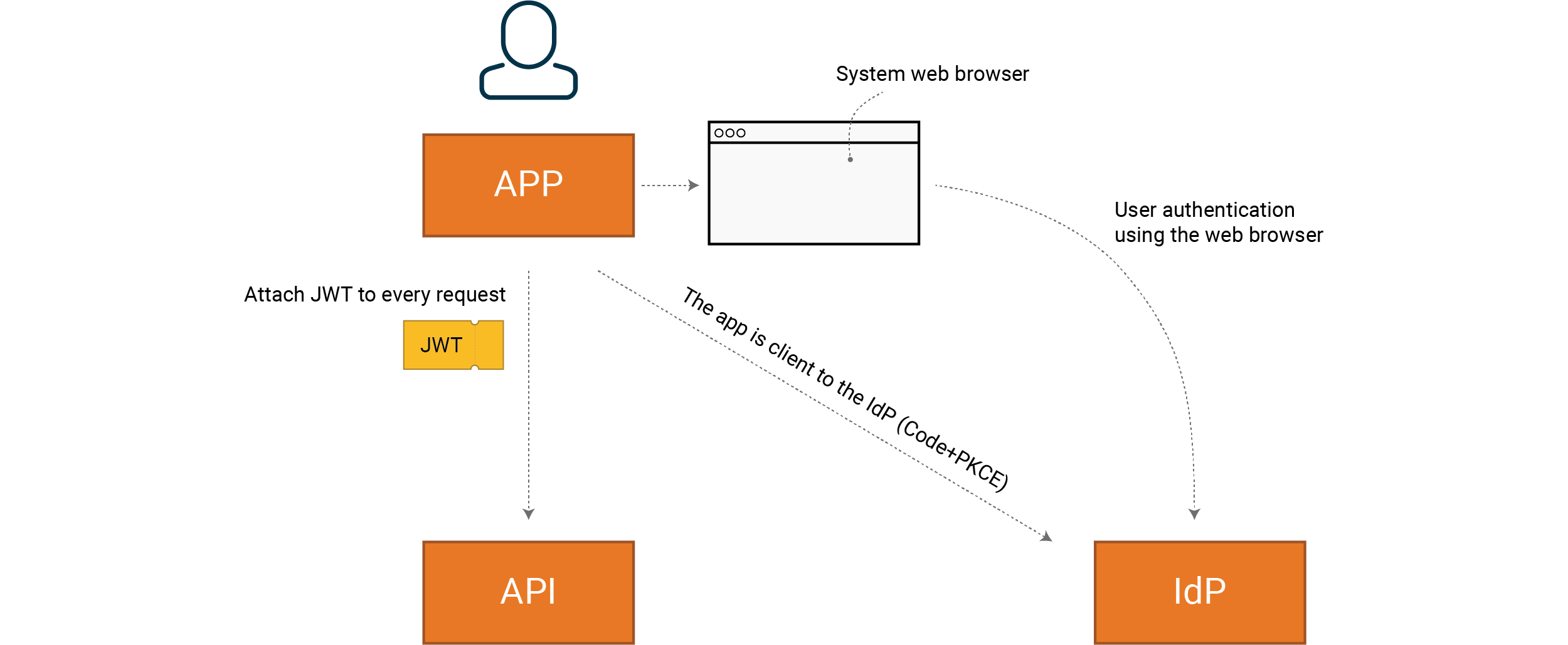 The client uses the system’s web browser to allow the user to authenticate
themselves to the IdP. We use a readymade library from the platform provider.
The client uses the system’s web browser to allow the user to authenticate
themselves to the IdP. We use a readymade library from the platform provider.
Tobias Ahnoff, Omegapoint
We often encounter a tension between good interaction design and secure MFA. This is especially true of mobile apps where it’s tempting to let the user enter their password directly in the app, instead of opening the system’s web browser. It’s important here to understand the user perspective and the possibilities afforded to us by OAuth2 and OIDC. What we want to find is a good balance between accessibility and confidentiality.
This is an area that is evolving, togheter with so called detached user authentication flows and integration with strong user authentication mechinsm on the device. Thus, it is common with custom flows, especially for first party applications.
Devices
When we have clients that either don’t have a web browser or have limited support for letting users enter text, we can apply a flow called “Device Authorization Grant”. Examples of clients are TV sets and IoT devices. An important type of client in many systems is a terminal (CLI) where this flow can offer the user a simple way of authenticating themselves.
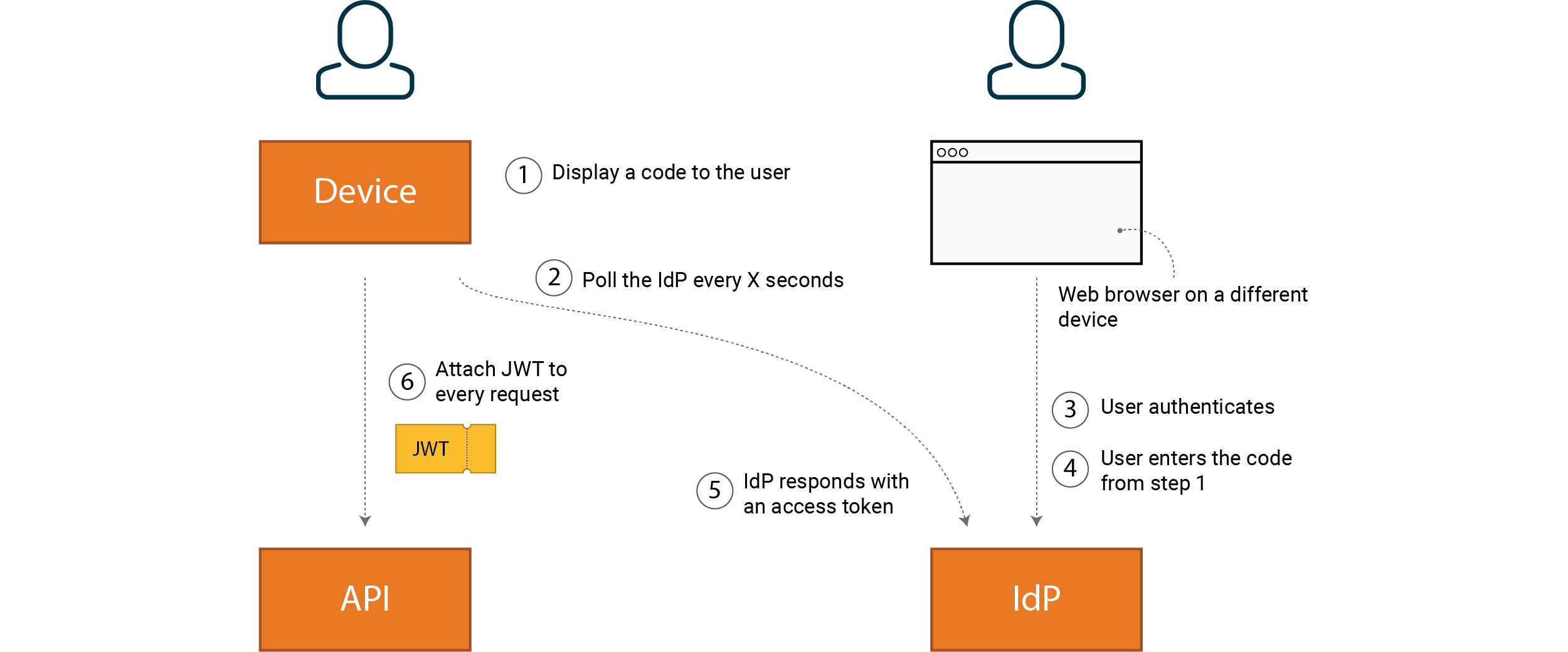 A user initiates sign-in, for example in a bash prompt. The sign-in command
returns a web address and code which all users can use for authentication on
another device.
A user initiates sign-in, for example in a bash prompt. The sign-in command
returns a web address and code which all users can use for authentication on
another device.
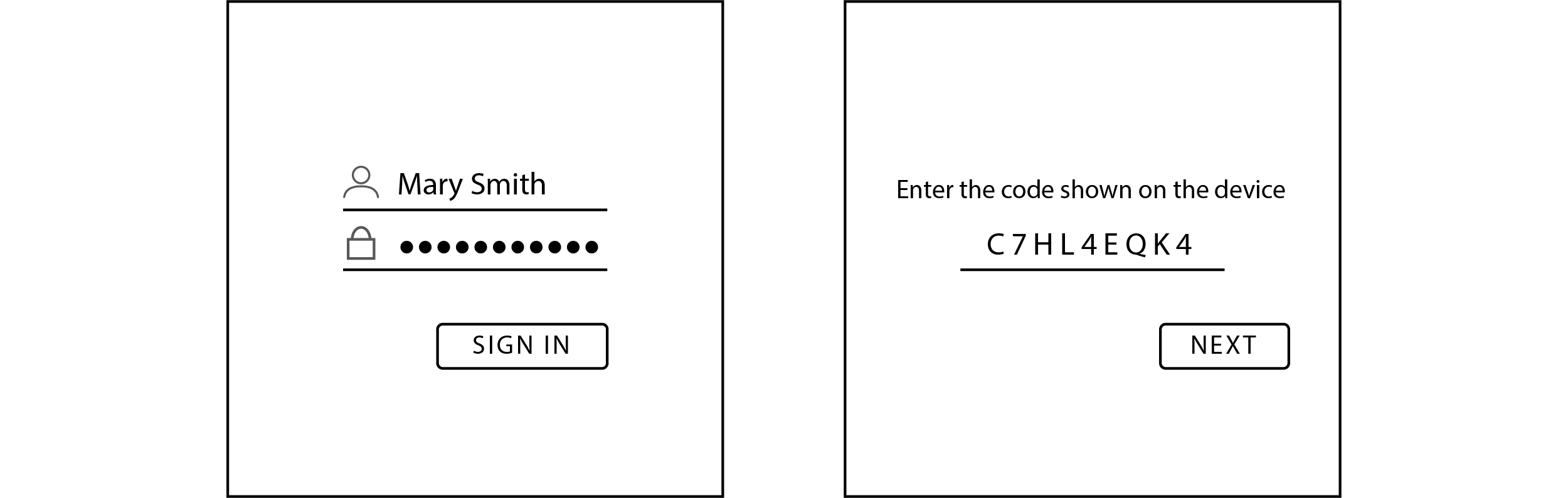
[anna@machine ~]$ signin
To sign in, use a web browser to open the page https://idp/device and enter
the code C7HL4EQK4 to authenticate
The user launches a web browser, navigates to the link above and authenticates themselves as usual. After successful sign-in, the user enters the code, which triggers an access token to be returned to the client (Device).
More information about this flow can be found at https://oauth.net/2/grant-types/device-code/
Summarizing clients and flows
We’ve taken a look at how different client types get hold of access tokens. We have four different client types and three basic flows with OAuth2.
| Client type | Flow |
|---|---|
| Service integration | Client Credentials |
| Web | Code |
| Native | Code |
| Devices | Device Code |
No matter the flow, we can strengthen our protection with mTLS or private-key-jwt for strong client authentication, sender-constrained tokens and reference tokens.
Martin Altenstedt, Omegapoint
An important architectural decision we make is to use BFF for SPAs. There are a lot of security benefits to using a BFF solution since we maintain security-critical code and the token in the backend.
The code flow should always be secured with PKCE, and for systems with higher security requirements, PAR should also be used, as recommended by FAPI, for example.
PAR is relatively new and gaining support from authoriztion servers. PAR strengthens protection in that a minimum of parameters pass via the web browser.
https://oauth.net/2/pushed-authorization-requests/
FAPI originated in the banking and finance sector, but in line with work on 2.0 these recommendations also apply to systems that require the same security level as “financial grade APIs”, e.g. health care.
Tobias Ahnoff, Omegapoint
Regardless of the level of security, FAPI is an excellent point of reference for how you should be building secure OIDC/OAuth2 implementations. With clear specifications and recommendations for IdP, client and API (resource servers).
Sessions
OAuth2 only defines delegation of authorization to a client, i.e. how you can give the client an access token securely. The basic scenario for OAuth2 is that the user gives a third-party client access to profile data from their Google account, for example. Often this access continues even after the user has left the application.
The strength of OAuth2 flows is that this all happens without the user revealing their secret to the third-party client. The secret, in this case their Google password, should stay between Google and the user.
However, this is not the same as a user logging in to the client and running an active session.
A session can be defined as a temporary and interactive exchange of data between a user and the system. The session is established at some point in time and ends at a later time. The lifetime of the session varies depending on the type of system. A banking application typically has short sessions, while an administrative system, for example, has significantly longer sessions.
Another important aspect of a user’s session is that we have a standardized way of representing the user’s identity. To achieve this, we use OpenID Connect (OIDC) which standardizes identity and also, to a certain extent, how sessions and Single Sign-On (and Single Logout), are handled.
Martin Altenstedt, Omegapoint
Before OIDC became established, many people came up with their own login solutions based on OAuth2 which often came with weaknesses. Examples include Facebook, Apple etc. Creating your own solutions is quite simply not a good idea here, even if you are a large organization.
OIDC is used on top of OAuth2, i.e. it’s still the same basic code flow for delegating authorization, and with an OIDC solution we have three different token types:
- ID tokens give the client the ability to validate user authentication and user identity
- Access tokens are used by the client to make requests to the service (often an API)
- Refresh tokens can be used by the client to request a new access token from the IdP without the user re-authenticating themselves, thus providing a way of handling long-term access to the user’s resources.
An example of an SPA implemented according to the BFF pattern would look like this
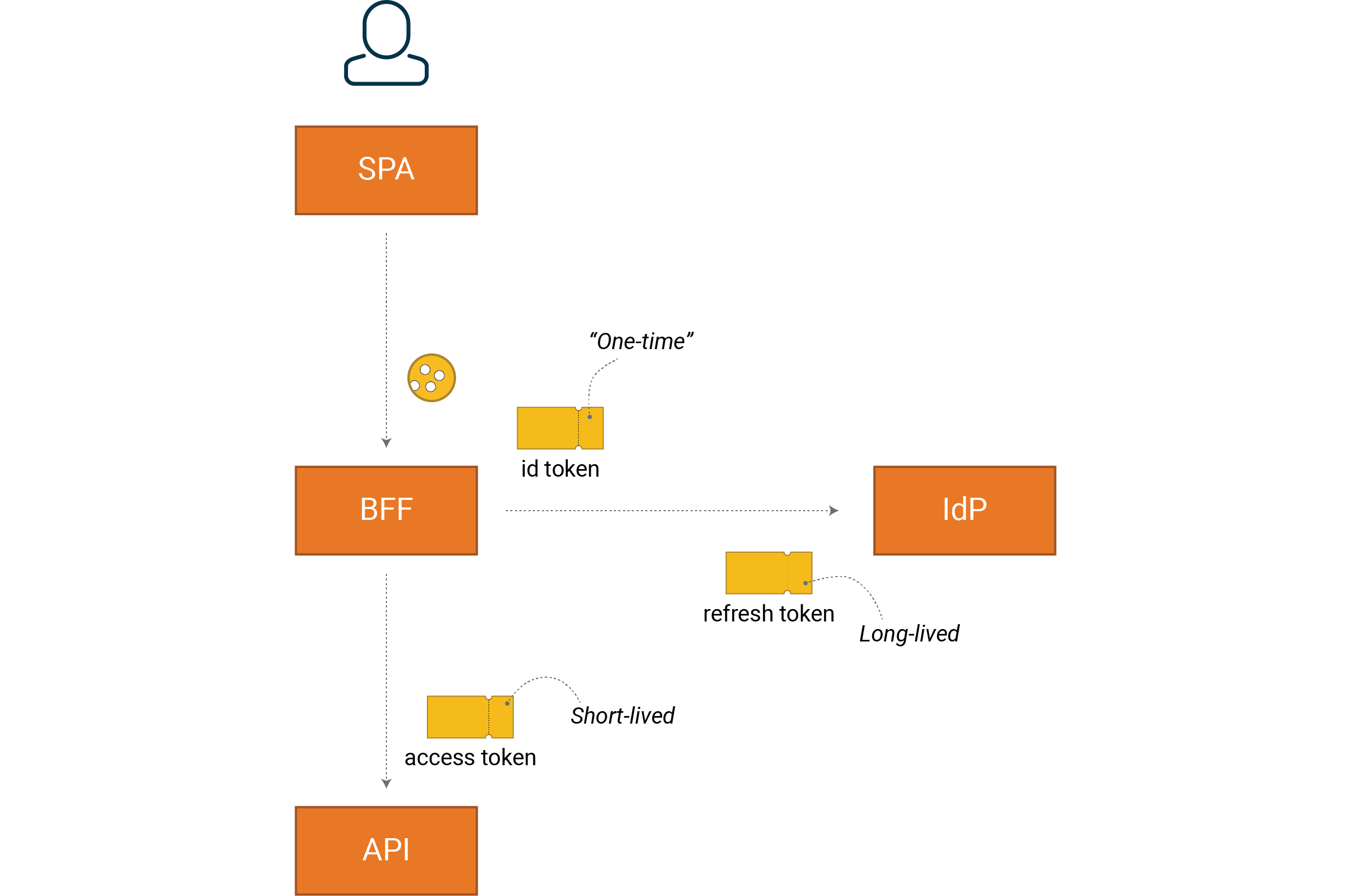
Since HTTP is stateless and we have a web browser as frontend, we create sessions using cookies. Note that all tokens are handled by the BFF (backend), i.e. they are not available for the SPA (JavaScript in frontend).
ID tokens are “one-time tokens” for the client that are not sent anywhere and that should be valid for as brief a time as possible, in practice around 5 minutes. Think “authentication response”, not token.
An ID token contains metadata from the authentication, i.e. what method was used, exact time etc. Unlike access and refresh tokens, ID tokens are specified via OIDC. An ID token also usually contains some information about the user, e.g. name, but this is not its primary purpose.
Kasper Karlsson, Omegapoint
Note that an ID token should not be accepted by an API as a valid access token – not even if it’s a JWT. This is something we sometimes come across in our pentests.
Our access tokens are often a JWT, or a reference token that can be translated into a JWT. This is used by our API where it forms the basis for our access control of requests.
Refresh token is a long-life token that is used to get a new, more short-lived access token from the IdP. This is a cryptographically secure random string, not a JWT.
Note that the refresh token flow is part of OAuth2, i.e. it can be used with or without OIDC and sessions to give long-term access for clients that are meant to access your resources even when you are inactive.
The refresh token flow works as follows.
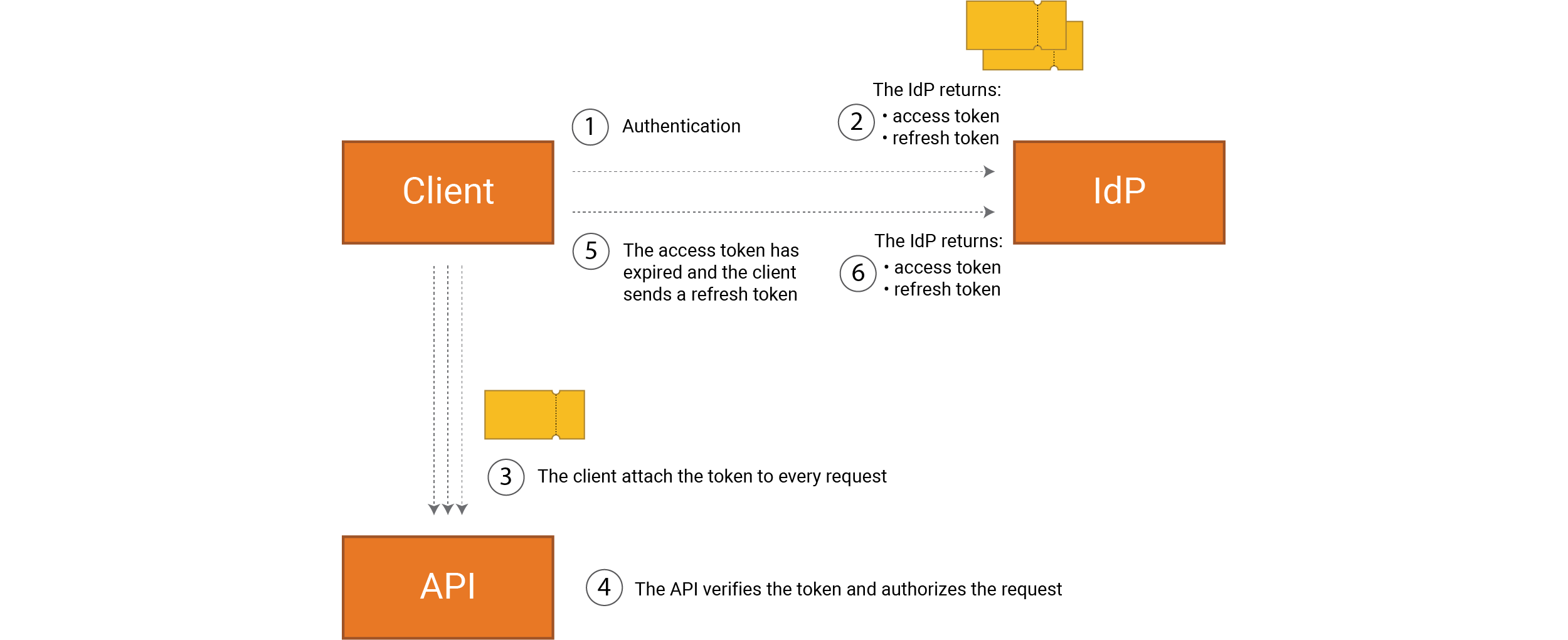 Note than when a refresh token expires, the user must re-authenticate
themselves. See more at
https://datatracker.ietf.org/doc/html/draft-ietf-oauth-v2-1-02#section-6
Note than when a refresh token expires, the user must re-authenticate
themselves. See more at
https://datatracker.ietf.org/doc/html/draft-ietf-oauth-v2-1-02#section-6
The issue we now face is connecting these tokens to a user’s session. It’s important to have control over sessions and a clear specification from the business. How often the user has to authenticate themselves is a crucial component of the user experience.
Tobias Ahnoff, Omegapoint
Often business stakeholders and UX departments focus on accessibility where login becomes a challenge or obsticle. But security also means confidentiality, integrity and sometimes even traceability. For banks, for example, we want to know that the user is present and actively making payments, and can also connect activities to them in a legal sense. It’s clear here how important it is to strike the right balance between all aspects of security.
Taking our SPA as an example, we get the following sessions to handle in a solution that uses OIDC. It’s important to understand that the cookie for BFF, together with the cookie for IdP, form a joint session on the system for the user. This requires an interaction between these two cookies and the lifetimes of our tokens.
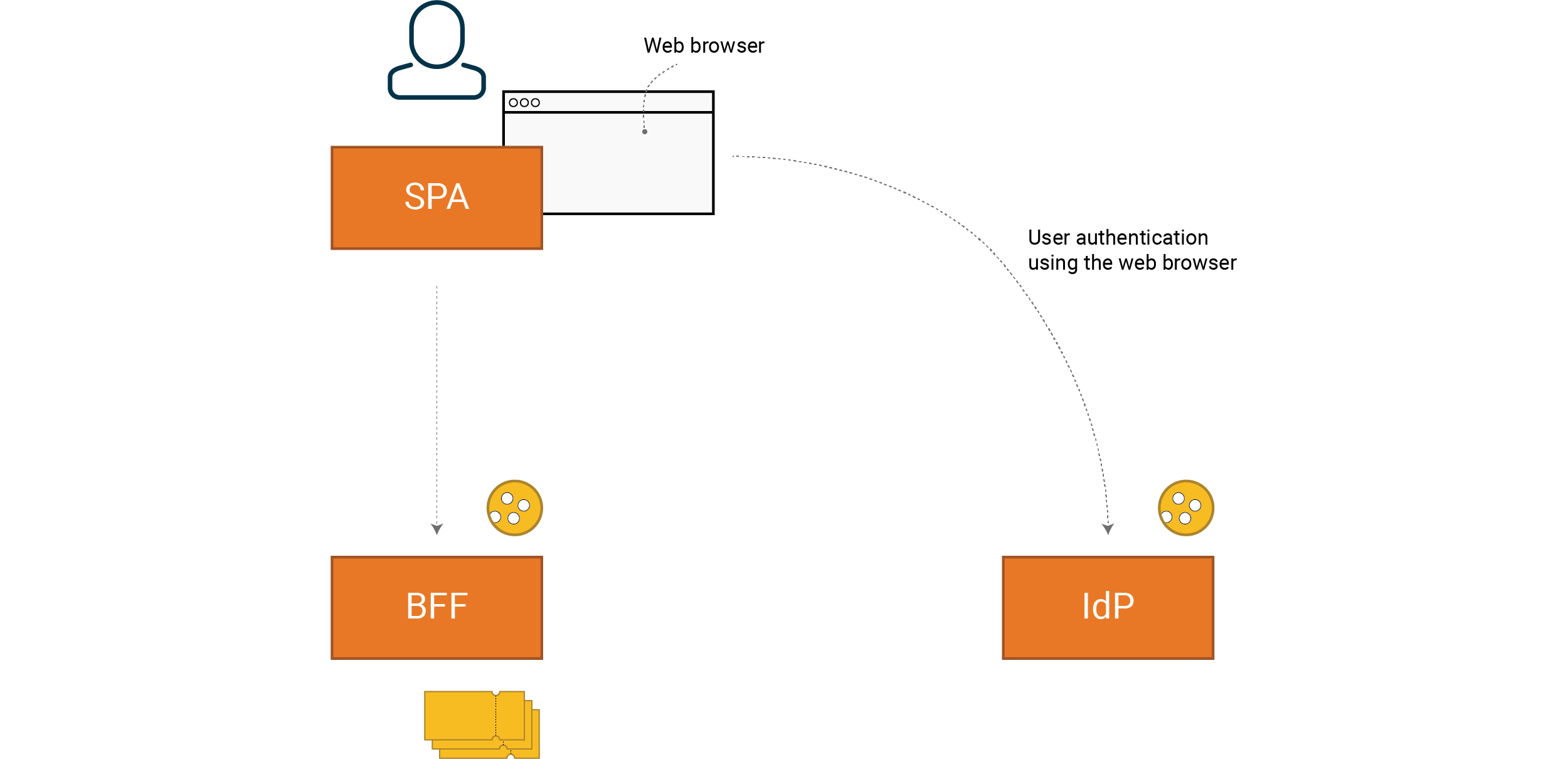 A typical OIDC solution produces two cookies and three tokens to keep an eye on. The
cookies between SPA and BFF, and between SPA and IdP. The cookie between SPA and
IdP gives us Single Sign-On, often called an SSO cookie.
A typical OIDC solution produces two cookies and three tokens to keep an eye on. The
cookies between SPA and BFF, and between SPA and IdP. The cookie between SPA and
IdP gives us Single Sign-On, often called an SSO cookie.
The lifetimes of sessions are essentially governed by two parameters:
- Inactivity, so-called “Sliding Window”
- Maximum lifetime
Kasper Karlsson, Omegapoint
It’s easy to forget about maximum length but it has a role to play in terms of security. Otherwise, an attacker who manages to steal a session can use it in perpetuity, even after you plug the gap that allowed the session to be stolen in the first place.
How often a user has to authenticate themselves depends to a great extent on your set of requirements. A bank, for example, might have inactivity of 5 mins and max. 60 mins. E-commerce may have inactivity of several weeks, with a maximum that may run into the months. In the example shown, we have 7 day of inactivity and 28 days max.

For the session regarding the BFF to work as expected, without unexpected re-authentication, the client (BFF) needs to have access to valid access tokens for the user for the entire session lifetime.
Since access tokens are short-lived, the refresh tokens need a validity that is synced with the session, or in our example: 7 days sliding, with max. 28 days.
Access tokens should always be short-lived; in our example, a reasonable time might be 60 mins, for a bank it could be 5 mins.
When the session ends, there should not be any active tokens left, but note that your last access token can remain valid after the session maximum and refresh token. Minutes almost never matter in practice, but days don’t fulfill a requirement where the user expects that data can only be obtained by the client during an active session.
The aim of a session with high security requirements is for us to be able to trust that the user who has authenticated themselves is present for the entire session, not just when logging in. This so that we also provide support for reliable traceability.
Martin Altenstedt, Omegapoint
A client that receives an access token is going to have access to my data for as long as the token is valid, regardless of whether or not I am physically still there. That’s why it’s important to require re-authentication for extra-sensitive operations. Think signing for payments.
We want to highlight the importance of clear session specifications, something that is often overlooked and perhaps left to the developer to implement. The following conversation captures many of the questions that come up when you’re implementing SSO solutions:
PO — What happens when a BFF session ends and we make a new request?
DEV — We get redirected to the IdP and if we have a valid SSO session then we don’t need to authenticate ourselves again there. Instead, we can come back and create a new BFF session directly. The user might only notice this because of the web browser’s address bar flashing.
PO — But if I’m at the IdP because I’ve been inactive for 7 days, don’t I need to authenticate myself again?
DEV — No, that’s correct, if your SSO session is longer than 7 days then you don’t need to authenticate yourself again.
PO — But that does not match my requirements? My specification said that it should require a new login after 7 days of inactivity?
DEV — Exactly, and to do that we need an interplay between SSO and the local session between SPA and BFF. In your case, you need an SSO session that has the same max and sliding as your BFF session.
PO — But what if I’m not the only system using the IdP and there are multiple systems, with other requirements for inactivity and maximum session lengths? There could be very different requirements from one system to another.
DEV — Yeah, that could be a problem, this is where different IdP products look different. Some allow us to configure an SSO session per client, but other products might not let us do that. The same goes for OIDC support where many products support what’s defined in the Core specification, but maybe not the Session specification.
Erica Edholm, Omegapoint
It can be tough to test how sessions are handled and this is something people can often overlook. As always, it’s important to remember the negative test cases and that security is one of many requirements, e.g. “If I as a user am inactive for X minutes, the next operation will not be performed without re-authentication”. Automated testing is tricky here and we often need to run manual tests, which produces long lead times and becomes tedious to repeat :-)
It’s important you sort out your requirements for sessions and SSO. The next section will adress additional requirements where we strengthen the protection around sessions, cookies and refresh tokens, and take a closer look at logout and impersonation.
Your choice of IdP product is also important as it needs to support your requirements, see more details in article How to choose in IdP.
Secure sessions
There are a few things we need to think about if we want to strengthen protection when using cookies. Essentially, our session cookie should only contain information that is required for the session.
Kasper Karlsson, Omegapoint
We’ve seen vulnerable systems where sensitive session data are stored in “ordinary” cookies. An attacker has managed to manipulate these cookies to gain access to other user accounts, for example, or even to change roles in order to increase the rights they have within the system.
These shall be cryptographically secure, i.e. either encrypted by BFF (backend) or the BFF needs to have its own session store (Redis is customary) for storing your session. Your session cookie can then instead contain a cryptographically secure ID only. The downside is that you are introducing a state here, but the flip-side is that you get a small payload for your requests (which otherwise often has to be split into several cookies).
We should also utilize the protection that web browsers provide in the form of
HTTPOnly and the Host prefix __Host-, for example, so that session cookies are
not available for Javascript and force secure use of the Domain, Path and Secure
attributes.
Wherever we use cookies, we also need to deal with Cross Site Request Forgery (CSRF). CSRF means that an attacker can exploit your session to conduct operations without you being aware of them. For example, you might be lured into clicking on a link that you don’t realize links to our system. This works because the browser automatically sends our session cookie together with every request to BFF, which applies to both read and write operations.
The different CSRF protections recommended by bodies such as OWASP can be divided into three levels and our experience has shown that the following, when taken together, provide strong CSRF protection:
- Web browser: SameSite cookie policy Strict or LAX
- Application: CSRF tokens, e.g. “double submit cookies” or equivalent depending on application and framework support
- User: Re-authentication/signing for sensitive operations (alternatively CAPTCHA solutions)
Even though SameSite offers protection, different browsers and versions make different assessments of what is OK according to the Strict or LAX policy. Which makes it difficult to know exactly how this protection will work in practice for different browsers over time. Therefore, based on our experience and OWASP recommendations, we should see SameSite as a complement to other forms of protection.
Karin Taliga, Omegapoint
Don’t forget about the accessibility aspect of security either. A problem that many of us who’ve worked on OIDC in recent years have come across is that logins fail because cookie policies are implemented differently in different browsers. This can be a tricky issue to troubleshoot and monitor, and things could get very serious for your business.
So regardless of any other CSRF protection you might have, re-authentication is a must for highly sensitive operations where we require traceability.
Björn Larsson, Omegapoint
Remember that XSS essentially bypasses all protection surrounding our session, except perhaps for strong re-authentication, so always prioritize protection against XSS when building web applications and build your security across several layers with defense in depth!
Secure refresh tokens
Refresh tokens are highly sensitive information and should therefore be kept on the backend, in an environment that we are fully in control of. This means they should not be available in browsers where you can access them via JavaScript, e.g. in an XSS attack.
Basic protection for refresh tokens also comes from the fact that they should always be bound to the client.
For confidential clients, a backend that we control (e.g. a BFF), we do this using client authentication every time a refresh token is refreshed.
For systems with high security requirements, all clients should be confidential. If we have public clients, we should avoid long-life refresh tokens for these clients. However, this is something you need to assess based on your specifications and risk analysis.
Tobias Ahnoff, Omegapoint
A common challenge is mobile apps which are public (native) clients requiring long-term access. It is often considered that the risk posed by using refresh tokens for these is acceptable. Assuming that you do what you can to protect these by using secure token storage and management. Note that to strengthen protection, OAuth 2.1 recommends that refresh tokens be one-time tokens, i.e. rotated on every refresh token request, and that “misuse protection” be applied. But, this could be problematic and in practice add little to security. As an exempel, the use if refresh token rotation is discuraged when using sender-constraind tokens (see note 1 in https://openid.net/specs/fapi-security-profile-2_0-final.html#section-5.3.2.1)
Identifying misuse is easier said than done, however. In practice, an IdP has a tough time determining whether some public client has stolen a token and is using it according to a normal pattern. A confidential client with a session, on the other hand, has better capabilities since the client can use its domain knowledge regarding what is a reasonable user pattern and can conduct a more in-depth analysis.
We also want to point out once more that for web applications you should be prioritizing protection against XSS. You might have done everything right in terms of how tokens and sessions are handled, but if you have an XSS vulnerability then an attacker can in principle bypass all of that protection.
Kasper Karlsson, Omegapoint
Whenever we conduct penetration tests on web-based systems, we almost alway find XSS vulnerabilities. An attacker can use these vulnerabilities to steal tokens – long-life refresh tokens, for example, can be particularly valuable for attackers.
Read more about penetration tests and common vulnerability types in the article Offensive application security.
We’ll come back to XSS and how to protect against its vulnerabilities in our article on web browsers
Single logout
Giving users a controlled way to end their session is crucial for a secure system and a good user experience. However, we can’t base our security on the assumption that users will actually log out. Quite the opposite, in fact, as it is our responsibility as client to do a proper cleanup for a user who actively logs out.
In an OIDC solution with SSO, we need both a local logout (1) and also a logout with respect to the IdP (2).
If you want to use Single Logout (3), then you also need a logout with respect to other clients that have SSO (for the same IdP). Which we then achieve using OIDC Back-channel logout where the IdP notifies all other clients that are registered for Single Logout.
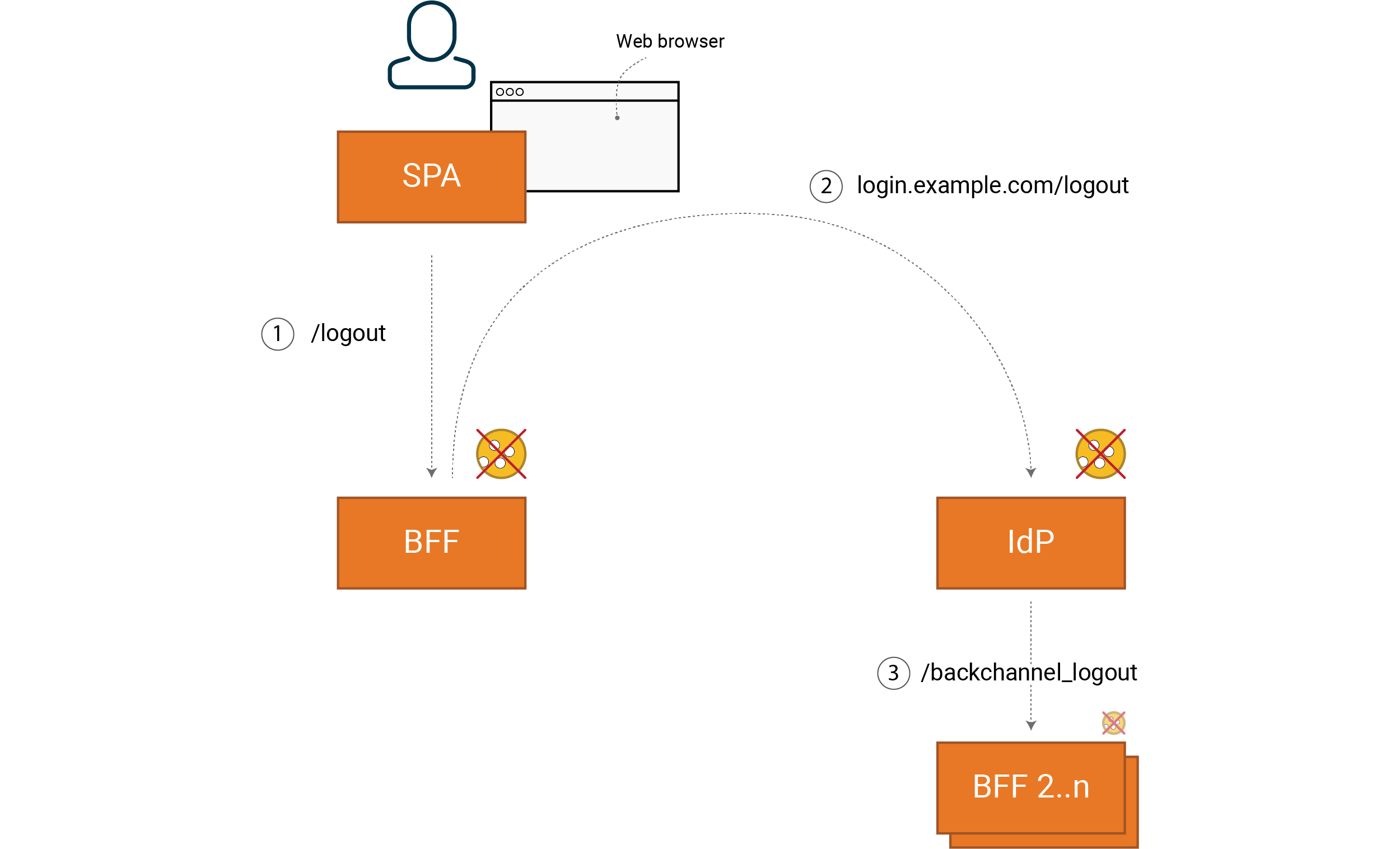 Note that Step 3 requires that the client (BFF) maintains the session’s backend
state, e.g. via a Redis cache. But even if we don’t require Single Logout, we
still need to maintain the session’s backend state in order to have full control
over our sessions. Whether or not it is motivated to introduce state-dependency,
however, depends on your system specifications.
Note that Step 3 requires that the client (BFF) maintains the session’s backend
state, e.g. via a Redis cache. But even if we don’t require Single Logout, we
still need to maintain the session’s backend state in order to have full control
over our sessions. Whether or not it is motivated to introduce state-dependency,
however, depends on your system specifications.
Martin Altenstedt, Omegapoint
A question we are often asked is how do administrators log someone else out or lock an account? When we have total control over our sessions, because we are managing the backend state, we can quite simply delete the user’s session in our BFF and IdP and trigger a Single Logout.
Tobias Ahnoff, Omegapoint
Achieving a good, consistent user experience for both SSO and logout, often takes more effort than you think. For example, there is a risk that your choice of IdP might limit you in terms of what you can do in connection with Single Logout.
Also, if all sessions are supposed to behave as a single session, you might want to think about whether this should be one application with a simple local session. Then you can avoid the complexity that comes with SSO and Single Logout. Keep this in mind: “Complexity is the worst enemy of security” and “You can’t secure what you don’t understand”. These qoutes are from the iconic blog https://www.schneier.com/essays/archives/1999/11/a_plea_for_simplicit.html. From 1999, but still worth a read!
Impersonation
In many systems, we have a requirement to act as someone else. This could be in customer support if we perhaps want to log in as a user to see what they can see, for example, or if we want to execute a task for them.
There’s a flow we can use for this called “token exchange”, which involves switching out our own token for a new one, but without losing who owns it.
In our example, “admin” has authenticated itself via a code flow, for example, so that the client has a valid access token for “admin”.
The client provides an interface so that “admin” can choose who is going to be impersonated, namely the “user” in our example. The client requests a token-exchange endpoint and together with this request it sends the access token for “admin”, and the “user” who is the target for impersonation (1).
IdP now needs to carry out access control to determine whether “admin” can conduct impersonation. IdP then returns a new access token, where the sub is “user”, and an act-claim with sub “admin” (2).

{
"aud": "https://api.example.com",
"iss": "https://issuer.example.com",
"exp": 1443904177,
"nbf": 1443904077,
"sub": "user@example.com",
"act": {
"sub": "admin@example.com"
}
}
Note that now, in its audit trail, an API can log that “admin” is the source of the operation even though it is being executed with the same access rights as “user”.
In the specification (https://datatracker.ietf.org/doc/html/rfc8693) this is called delegation. This is different from impersonation where you don’t have the ability to determine who is the owner, as is the case in this example if you don’t have an act-claim as well.
Different IdP products have different approaches to supporting this and similar scenarios so check your product documentation to see how it works for your solution.
Summary
The first three articles give you the tools you need to be able to build strong and fine-grained access control for our system.
In the first article, we looked at how we can model identity using the concepts and tools that OAuth2 and OpenID Connect give us.
Article 2 discussed how we should approach the decision of what information should be contained in our access token, and how we go from token to rights and access control in our APIs.
In this article, we’ve looked at how to get an access token for different client types, and how we handle our sessions, and SSO and Single Logout.
Our next article will tell you what you need to build a secure API with strong access control.
See Defense in Depth for additional reading materials and code examples.
More in this series:
- Defense in Depth: Identity modelling (part 1/7)
- Defense in Depth: Claims-based access control (part 2/7)
- Defense in Depth: Clients and sessions (part 3/7)
- Defense in Depth: Secure APIs (part 4/7)
- Defense in Depth: Infrastructure and data storage (part 5/7)
- Defense in Depth: Web browsers (part 6/7)
- Defense in Depth: Summary (part 7/7)