Defense in Depth: Claims-based access control (part 2/7)
6 November 2025In the previous article, we talked about what information we require to achieve strong access control. This article looks at how we transfer information on what scopes and audiences the user has approved, their identity and details on their login, plus rights we use for access control.
To build a working solution, we need to introduce two new concepts: Access token and Identity Provider (IdP). The format of an access token can vary. For a REST API, it’s customary for the access token to be a JSON Web Token (JWT). This article was written based on a JWT example, but the fundamental concept and reasoning behind it can be applied to any token format.
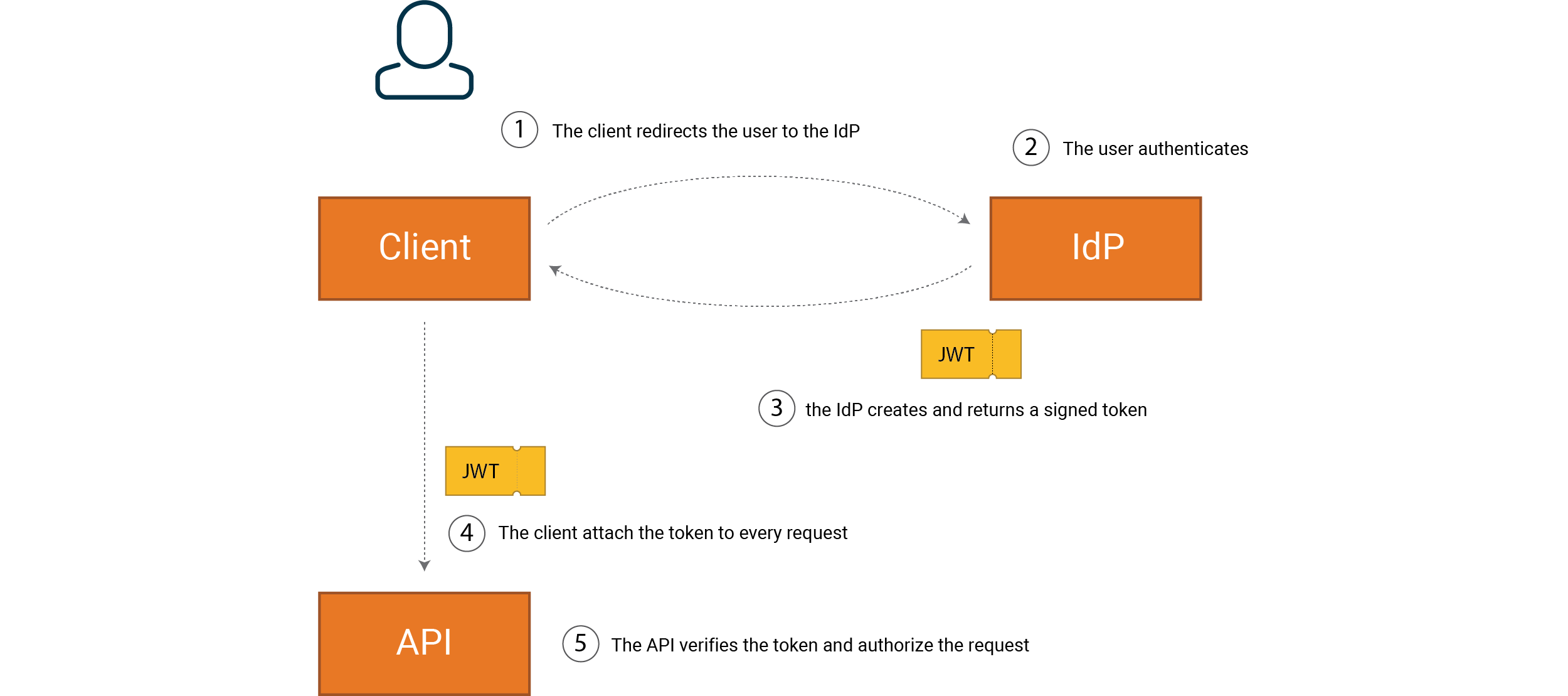 Overview of how a token is created and then sent from client to API
Overview of how a token is created and then sent from client to API
IdP, AS, STS, etc., our dear child has many names, and while there are differences between them, we have chosen in this article to use the term IdP to indicate the service you authenticate yourself to and from which you get your tokens.
A JWT is created by an IdP and is comprised of cryptographically signed ‘claims’. An example might be:
{ "sub": "8256-0346-3829", "name": "Eva Svensson" }The specifications for both JWT and OpenID Connect define a set of standardized claims. The “sub” element is central and is a unique identifier for the referred user. Note that the identifier should ensure anonymity and not reveal personal data or other sensitive information.
In our example, the user might be authenticating themselves using BankID. In that case, our IdP needs to look up a unique and anonymous identifier to avoid the user’s personal ID number being exposed more than necessary.
https://tools.ietf.org/html/rfc7519#section-4.1
https://openid.net/specs/openid-connect-core-1_0.html#StandardClaims
In addition to the user’s identity, a JWT from an IdP also contains information from the user’s authentication, e.g., used login type. This might be useful in terms of requiring a stronger form of strong authentication for particularly sensitive operations, for example.
The same principle also applies to integrations (service to service) that do not involve any users. In this case, our JWT does not contain any user ID, and instead, we use the client’s ID.
In practice, the claims contained in our JWT represent a contract between the IdP and the services. If your IdP adds any claims beyond the standard ones, you need to think about backward compatibility and how you manage changes as the system develops. Deciding which custom claims your IdP should include in your JWT is a balancing act. In principle, the information should be about identity, not access.
Take the following example of a JWT with a custom “admin” claim:
{ "sub": "8256-0346-3829", "name": "Eva Svensson", "admin": true }A potential problem with “admin” in a slightly larger organization is that there may be many different types of administrators, and we will have to add more and more claims as the system grows. So instead of “admin”, perhaps selecting one or two of the Active Directory groups Eva belongs to is a better choice? That way, each API can decide what a group means, hence we achieve a more stable solution. In that case, an example of claims in our JWT would instead be:
{ "sub": "8256-0346-3829", "name": "Eva Svensson", "groups": ["S-1-0", "S-1-1"] }The number of groupings we add can grow to an impractical level. One alternative is to forgo groupings altogether and instead to look up the information directly from each API. You should also make sure you don’t add dynamic information that changes over a token’s lifetime.
The more systems share the same IdP, the more important the balance of claims your IdP returns. There are often a number of domain concepts common to all systems within a company, and including an IdP in these can be beneficial. Alongside groups in the Active Directory, this could also be customer numbers or the like.
Concepts such as roles and other accesses often depend on context and API. A better approach is to start by having each API look up roles as part of the transformation to a local rights model based on the user’s identity.
The reason we are emphasizing that your JWT should be small and only include identity is because this will help with system performance and make it easier to expand your system with new subsystems that use the same IdP.
Your JWT is sent together with an HTTP header in every network request. A smaller JWT, with local, cached access lookups in your API, can help you achieve significantly better system performance than a larger JWT that contains multiple claims.
As you expand your system by adding multiple subsystems that use the same IdP, the question of how your JWT can grow becomes all the more important. Limiting the size of HTTP headers and cookies can be problematic. A small JWT is a better starting point and one that offers you greater freedom and leeway in the future.
In our experience, this balance between local and central rights models is key to the flexibility of your solution.
Since a JWT is signed cryptographically and is included in every request from the client, an API can verify that the claims that are included in a request come from a source we trust. The job of our API will be:
- To validate that the JWT is correct
- To transform the JWT into a rights model
- To validate access
Step 1 ensures the framework we build our API on. Step 2 you will have to implement yourself, and Step 3 is part of your application and domain logic.
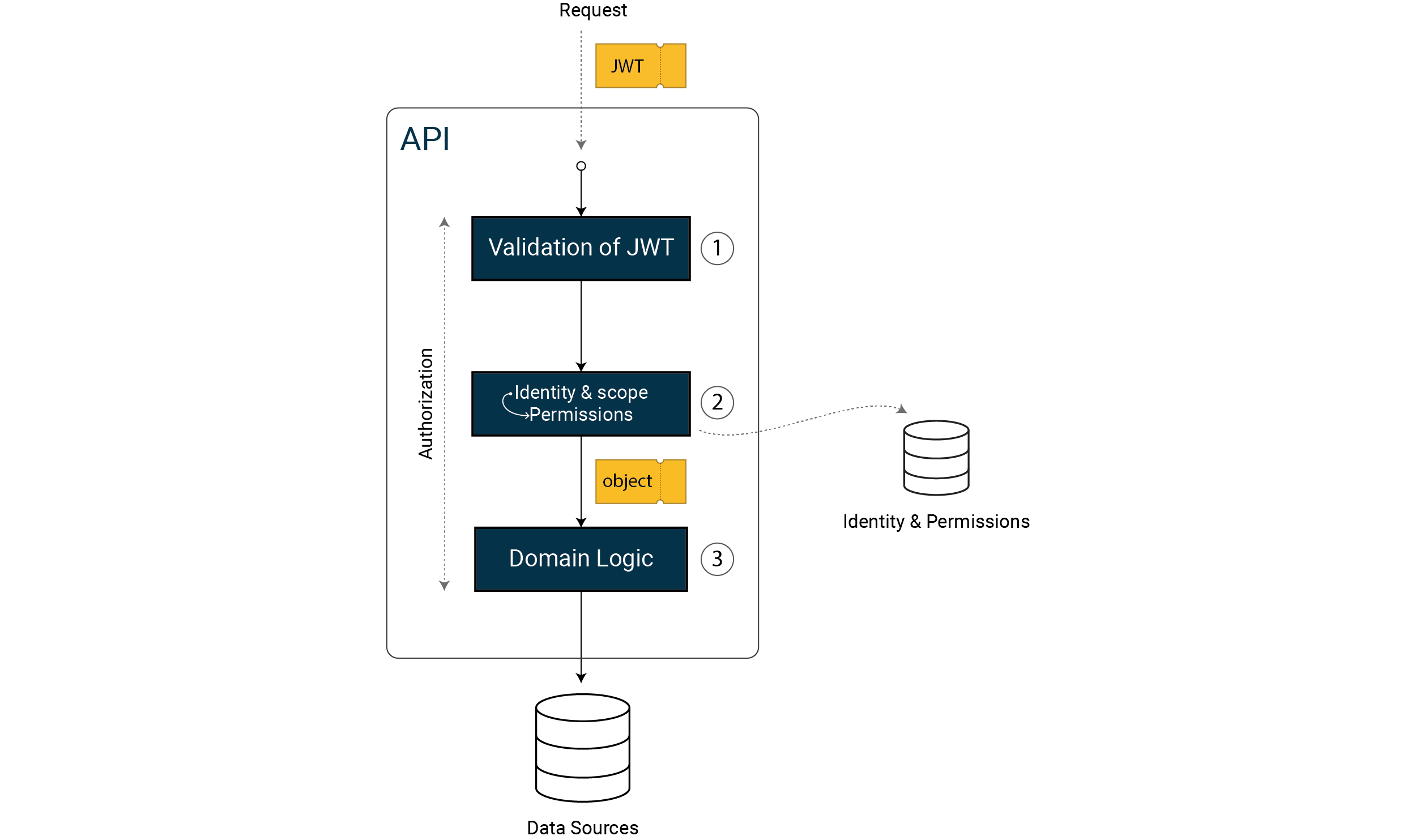 We move from a JWT to an object that represents our rights model by performing a
lookup against the rights model that has been configured.
We move from a JWT to an object that represents our rights model by performing a
lookup against the rights model that has been configured.
In Step 2, we transform the information we received in the form of claims in our JWT into an object of our rights model. This object contains all the information we need in our domain logic to investigate whether the user has a right to the function and requested data.
From this point on, we are working solely with our permissions object, not the information from our JWT.
In the transformation, you look up properties that affect the user’s access right. For example, which roles they belong to, what type of license they have purchased etc. This might mean that you will have to make a request (or call) to a shared service or consult a local database.
function transform(JWT)
if JWT represents an authenticated request
scopes := scopes from JWT
organization := organization from JWT /* Organization is a custom claim */
roles := get roles from service by JWT/sub /* Network call or database access */
permissions := intersection of scopes, roles and organization
return new Permissions(permissions, JWT/sub)
end if
return empty Permissions
In order to achieve access control and traceability across all operations in the system, the resulting object with the permissions model needs to continue all the way down to our domain logic. This allows us to make decisions regarding access rights without relying on claims, protocols and OAuth flows.
Note that this pattern handles all request types, regardless of whether they involve a user or originate from an integration (service to service).
In our experience, it’s a good idea to keep the transformation from claims to permission object in one class. Test-driven development is a hugely powerful tool for developing and maintaining this critical component.
Erica Edholm, Omegapoint
I often see us forgetting to write tests that verify access to the system. Writing tests is easier when the code is well-structured, and the transformation between identity and permissions one place.
Test cases I also like to see are
should_return_403_when_not_adminandshould_return_404_when_not_my_data.
See Defense in Depth for additional reading materials and code examples.
More in this series:
- Defense in Depth: Identity modelling (part 1/7)
- Defense in Depth: Claims-based access control (part 2/7)
- Defense in Depth: Clients and sessions (part 3/7)
- Defense in Depth: Secure APIs (part 4/7)
- Defense in Depth: Infrastructure and data storage (part 5/7)
- Defense in Depth: Web browsers (part 6/7)
- Defense in Depth: Summary (part 7/7)